使用 MTR 诊断因果集群中的网络延迟
MTR 是一个基于 ICMP 的简单测试工具,结合了 ping 和 traceroute 的功能。以下内容演示了如何使用 MTR 跟踪工具来诊断因果集群中的网络延迟和数据包丢失。该工具通常通过 WinMTR 工具在 Windows 上使用 (https://sourceforge.net/projects/winmtr/),但本文描述了其在 Unix 终端上的示例用法。安装和各种使用选项超出了本文的范围。有关这些内容的良好参考资料可在本文末尾引用的 Linode 网站上找到。
OSX 安装
$ brew install mtr这应该允许以 sudo /usr/local/sbin/mtr 方式执行,然而,执行以下两个命令可以简化为 sudo mtr 方式执行
$ sudo ln /usr/local/Cellar/mtr/0.92/sbin/mtr /usr/local/bin/mtr
$ sudo ln /usr/local/Cellar/mtr/0.92/sbin/mtr-packet /usr/local/bin/mtr-packet要使用 MacPorts 安装,请运行
$ port install mtr参数
| 用法 | 详细版本 | 描述 |
|---|---|---|
-F |
--filename FILE |
从文件读取主机名 |
-4 |
仅使用 IPv4 |
|
-6 |
仅使用 IPv6 |
|
-u |
--udp |
使用 UDP 而不是 ICMP echo |
-T |
--tcp |
使用 TCP 而不是 ICMP echo |
-a |
--address ADDRESS |
将出站套接字绑定到 ADDRESS |
-f |
--first-ttl NUMBER |
设置起始 TTL |
-m |
--max-ttl NUMBER |
最大跳数 |
-U |
--max-unknown NUMBER |
最大未知主机数 |
-P |
--port PORT |
TCP、SCTP 或 UDP 的目标端口号 |
-L |
--localport LOCALPORT |
UDP 的源端口号 |
-s |
--psize PACKETSIZE |
设置用于探测的数据包大小 |
-B |
--bitpattern NUMBER |
设置有效载荷中使用的位模式 |
-i |
--interval SECONDS |
ICMP echo 请求间隔 |
-G |
--gracetime SECONDS |
等待响应的秒数 |
-Q |
--tos NUMBER |
IP 头中的服务类型字段 |
-e |
--mpls |
显示来自 ICMP 扩展的信息 |
-Z |
--timeout SECONDS |
保持探测套接字打开的秒数 |
-r |
--report |
使用报告模式输出 |
-w |
--report-wide |
输出宽报告 |
-c |
--report-cycles COUNT |
设置发送的 ping 次数 |
-j |
--json |
输出 json 格式 |
-x |
--xml |
输出 xml 格式 |
-C |
--csv |
输出逗号分隔值 |
-l |
--raw |
输出原始格式 |
-p |
--split |
分割输出 |
-t |
--curses |
使用 curses 终端界面 |
--displaymode MODE |
选择初始显示模式 |
|
-n |
--no-dns |
不解析主机名 |
-b |
--show-ips |
显示 IP 地址和主机名 |
-o |
--order FIELDS |
选择输出字段 |
-y |
--ipinfo NUMBER |
选择输出中的 IP 信息 |
-z |
--aslookup |
显示 AS 号 |
-h |
--help |
显示此帮助并退出 |
-v |
--version |
输出版本信息并退出 |
以下示例仅描述了在 OSX 上的用法,但其在其他操作系统上的用法非常相似。
用法
sudo mtr <destination domain name or ip>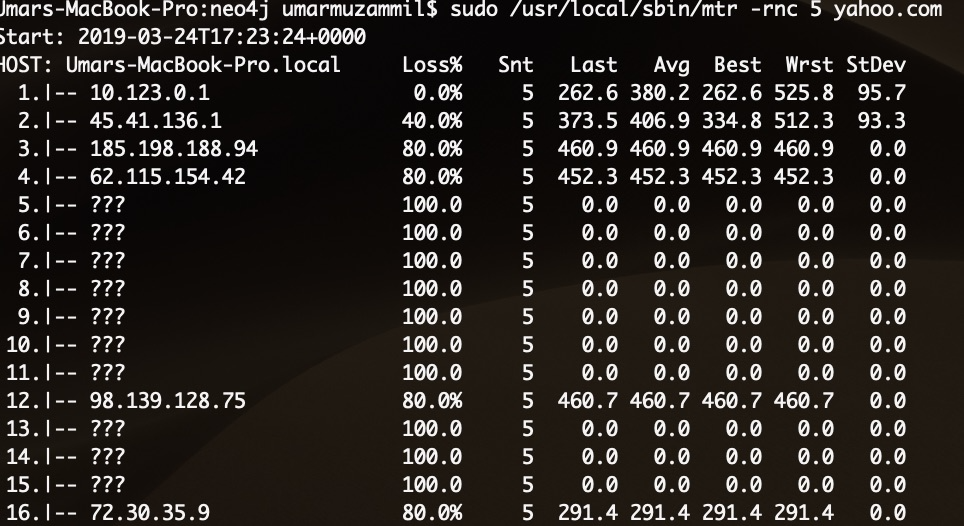
如果需要摘要而不是实时响应更新,请执行
sudo mtr -rwn -i 2 -c 5 <domain name or ip> > /User/<username>/Desktop/mtr.txt 其中 i 是 ping 间隔(以秒为单位),在此处为 2。这会将跟踪报告输出到上述指定位置的 mtr.txt 文件中。
运行 mtr -P <tcp port> -T -w <destination ip> 生成报告。默认情况下,它向主机发送 10 个数据包。Loss% 列显示每个跳点的丢包百分比。Snt 列计算发送的数据包数量。
接下来的四列 Last、Avg、Best 和 Wrst 都是以毫秒为单位的延迟测量值。Last 是发送的最后一个数据包的延迟,Avg 是所有数据包的平均延迟,而 Best 和 Wrst 显示数据包到达此主机的最佳(最短)和最差(最长)往返时间。在大多数情况下,应关注平均 Avg 列。最后一列 StDev 提供到每个主机的延迟标准差。标准差越高,延迟测量值之间的差异越大。
在分析 MTR 输出时,您需要查找两件事:丢包和延迟。以下是 mtr -P 80 -T -w <ip> 的示例测试结果
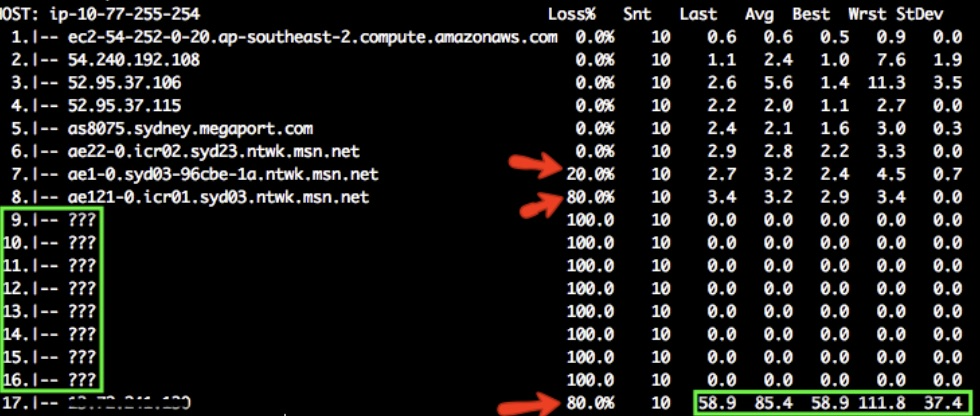
当没有额外的路由信息时,会出现问号 ???。在上面的示例中,从跳点 9 到 16 没有太多可用信息。当跳点之间报告可变丢包时,建议信任后续跳点的响应时间。
在上面的示例中,从跳点 6 到跳点 7 有 20% 的丢包,从跳点 7 到跳点 8 有 80% 的丢包。目标也存在 80% 的丢包。这可能导致高延迟(10 秒级),在这种情况下,这似乎归结于跳点 6、7 和 8。请注意,某些丢包是由于速率限制造成的。如果目标没有丢包,则表示连接良好。请注意,上述延迟平均为 86.4 毫秒。在这种情况下,跳点 8 到 16 似乎引入了大约 100 毫秒的延迟。
指定源地址和端口的能力,使得该工具对于测试集群内部延迟特别有用。可以指定源地址和端口以及要使用的协议(而不是 ICMP),例如 UDP 或 TCP。
例如,如果 Neo4j 服务器端设置了 dbms.connector.bolt.listen_address=:7688,那么通过执行 MTR 跟踪,从服务器到客户端测试将添加到查询响应时间中的网络延迟可能很有用,例如:sudo mtr -rwn -i 2 -c 5 -P 7688 -T <客户端 IP 或另一个集群成员 IP>。
对于一个样本的 3 核因果集群,如果配置了 dbms.connector.bolt.listen_address=:7688, dbms.connector.bolt.listen_address=:7689 和 dbms.connector.bolt.listen_address=:7690,我们可以测试实例 1(源)和 2(目标)之间的集群内延迟,例如:sudo mtr -c 5 -T -P 7689 192.168.8.103

此页面有帮助吗?