比较美国两代人的饮食习惯
比较美国两代人的饮食习惯
Alicia Powers <apowers411@gmail.com>
twitter: @apowers411
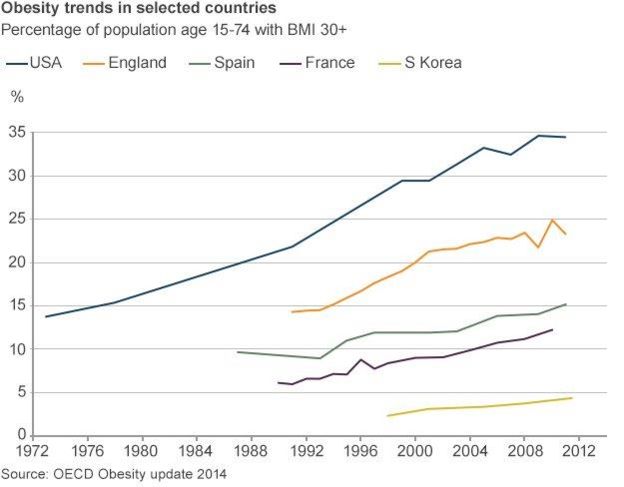
作为Neo4j的入门介绍,我使用了来自疾病控制与预防中心发布的国家健康与营养检查调查的开源数据,以考察美国人的饮食习惯。当我在Twitter上看到下面的图表时,受到了启发,决定研究这个问题。该图表显示,近年来许多国家的肥胖率有所上升。我好奇肥胖率的上升是由于年轻人的饮食习惯较差和BMI较高,还是老年人的BMI和不良饮食习惯也在增加。了解代际差异的一种方法是研究不同年龄段人群的饮食方式。
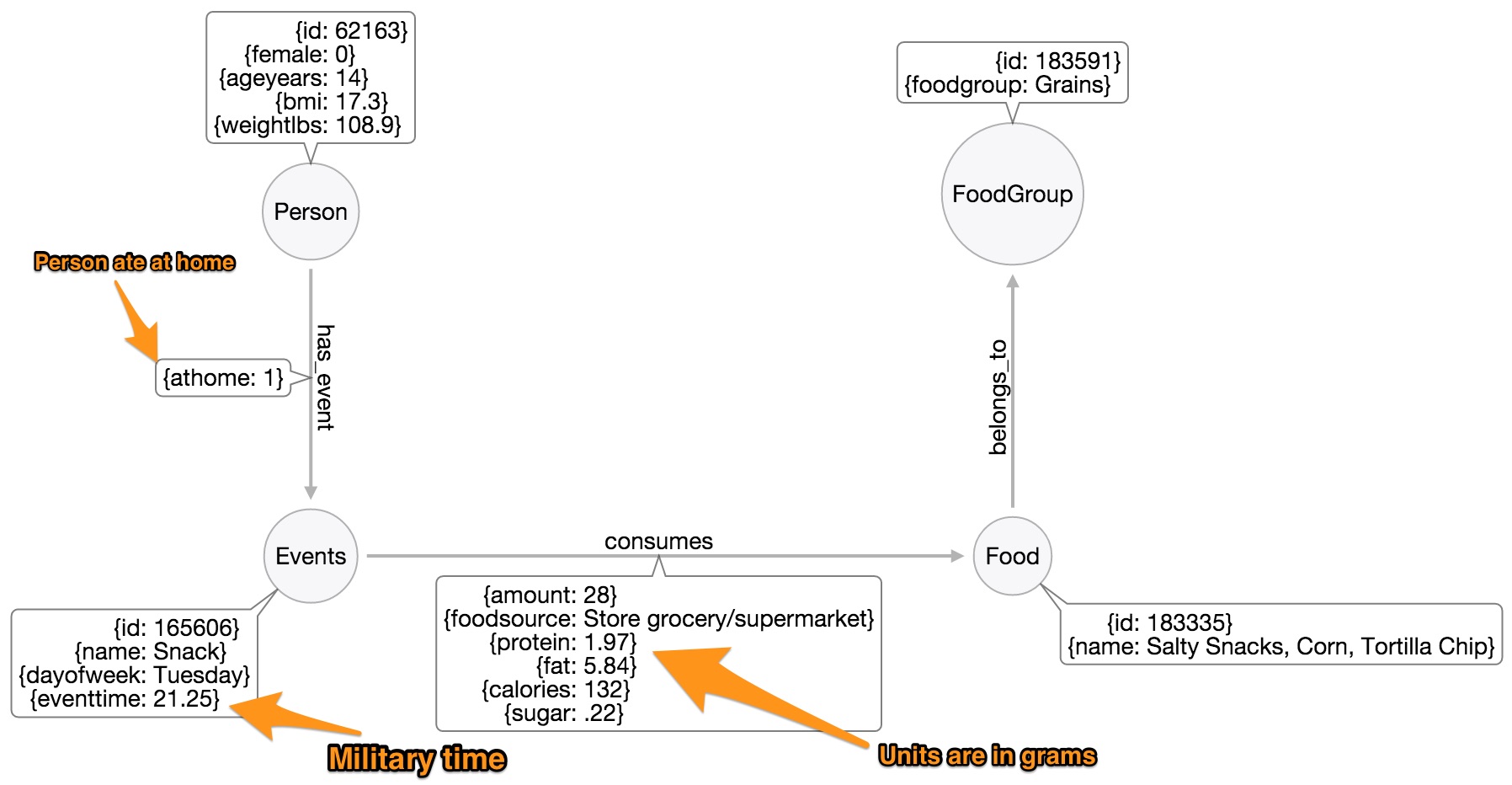
利用现有数据,我创建了下面概述的模型。每个人都由一个节点表示。节点上的标签是该人的年龄(以年为单位)。本例仅包含年龄在14至22岁以及65岁以上的人群,以便我可以考察两代人。每个个人节点上都包含其他人口统计信息(例如性别、BMI和体重(磅))。这项调查追踪了人们两天的饮食情况。
每个个人节点通过关系'has_event'连接到至少一个饮食事件节点。这些饮食事件节点代表零食、正餐和饮料等。饮食事件具有诸如饮食事件的时间和日期等属性。'has_event'关系具有事件是在家发生还是在外发生的属性。
事件(即正餐)通过关系'consume'链接到食物节点。'consume'关系的属性详细说明了此人摄入的食物量及其营养信息。最后,每种食物都使用'belong_to'关系连接到食物组。
此查询设置约束并导入个人级别数据。节点标签是每个人的年龄。本次Gist仅导入了19人。数据还包括每个人的BMI。BMI低于25为正常。BMI在25到29.9之间被认为是超重,BMI超过30是肥胖。
CREATE CONSTRAINT ON (c:Person) ASSERT c.id is UNIQUE;
CREATE CONSTRAINT ON (e:Events) ASSERT e.id is UNIQUE;
CREATE CONSTRAINT ON (f:Food) ASSERT f.id is UNIQUE;
CREATE CONSTRAINT ON (fg:Food) ASSERT fg.foodgroup is UNIQUE;
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "https://raw.githubusercontent.com/drpowpow/GraphGist/master/peoplegist.csv" AS line
CREATE (person:Person {id: line.id, ageyears: toFloat(line.ageyears), female: toInt(line.female),bmi:toFloat(line.bmi), weightlbs:toFloat(line.weightlbs)})
RETURN person现在将额外的食物、事件和食物组节点添加到人物节点。
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "https://raw.githubusercontent.com/drpowpow/GraphGist/master/eventswithfoodgist.csv" AS line
MERGE (event:Events {id: line.mealid,name:line.eventname, dayofweek: line.dayofweek, eventtime:toFloat(line.eventtime)})
MERGE (food:Food {id:line.foodid, name:line.name})
MERGE (foodgroup:FoodGroup {foodgroup:line.FoodGroup})本节添加事件。图表可读。
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "https://raw.githubusercontent.com/drpowpow/GraphGist/master/eventswithfoodgist.csv" AS line
MATCH (person:Person {id:line.personid}),(event:Events {id:line.mealid})
MERGE (person)-[:has_event {athome:line.eathome}]->(event);本节添加食物。图表变得更复杂。
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "https://raw.githubusercontent.com/drpowpow/GraphGist/master/eventswithfoodgist.csv" AS line
MATCH (event:Events {id:line.mealid}),(food:Food {id:line.foodid})
MERGE (event)-[:consumes {fat:line.fat,sugar:line.sugar,protein:line.protein,fiber:line.fiber,amount:line.amount,calories:line.calories,foodsource:line.foodsource}]->(food)本节添加食物组。图表变得难以阅读。
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "https://raw.githubusercontent.com/drpowpow/GraphGist/master/eventswithfoodgist.csv" AS line
MATCH (food:Food {id:line.foodid}),(foodgroup:FoodGroup {foodgroup:line.FoodGroup})
MERGE (food)-[:belongs_to]->(foodgroup)完整图表在此。
现在,我使用查询来探索一些数据。请记住,这不是科学分析。这些查询旨在理解数据,以便我们在查询整个图表时能够提出详细且有意义的问题。首先,我查看了两个人的图表,一个老年人,一个年轻人。
这是一位老年人
您可以看到这个人喝很多水,很少吃零食,并且似乎不喜欢蔬菜。您能猜出他们的BMI吗?(提示:在上面的表格中)
MATCH (me:Person)-[:has_event]-(meal)-[:consumes]->(food)-[:belongs_to]->(fg)
WHERE me.ageyears=75
RETURN me,meal,food,fg
limit 50这是一位年轻人
这个人经常吃东西,食物种类繁多,尤其是在早餐时间。这个人喝很多水,并且吃大部分食物组的食物。您能猜出他们的BMI吗?(提示:在上面的表格中)
MATCH (me:Person)-[:has_event]-(meal)-[:consumes]->(food)-[:belongs_to]->(fg)
WHERE me.ageyears=18
RETURN me,meal,food,fg
limit 50让我们看看人们的食物来自哪里。年轻人更倾向于在餐厅、餐车和自动售货机用餐。我个人惊讶地发现只有老年人吃自己种植或捕获的食物。
MATCH (p:Person)-[v:has_event]->(e:Events)-[r:consumes]->(f:Food)
WITH r.foodsource as Foodsource, count(*) as Total,avg(p.ageyears) as Average_Age, avg(p.bmi) as Average_BMI
Return Foodsource, Total, Average_Age, Average_BMI
ORDER BY Foodsource,Total DESC让我们看看平均而言谁在吃哪些食物组的食物。食物组的定义比较宽松。我知道酒精不是一个食物组,但它是对数据进行分类的一个简单方式。看起来老年人比年轻人喝得多得多。此外,糖替代品主要由老年人使用。年轻人几乎只喝运动饮料,以及吃鱼和海鲜。我确定其中一些发现是由于只查询了图表的一小部分,但这里有一些趋势,在查询完整图表时可能会看到。
MATCH (n:FoodGroup)-[:belongs_to]-(f)-[]-()-[]-(p)
RETURN n, count(f) as Foods,avg(p.ageyears) as Average_Age ,avg(p.bmi) as Average_BMI
LIMIT 25让我们看看平均而言谁在吃哪些食物。这是一个很长的表格,但信息量很大。我在这里使用了collect,这样我就可以看到每个年龄段有多少人在吃某种特定的食物。BMI仅作为参考添加。
MATCH (p:Person)-[v:has_event]->(e:Events)-[r:consumes]->(f:Food)
WITH f.name as Foods, count(*) as Total,collect(p.ageyears) as Ages,collect(p.bmi) as BMI
Return Foods, Total, Ages,BMI
ORDER BY Foods,Total DESC此页面有帮助吗?