健身与营养建议
介绍
最近,我受到启发,希望将BeachBody健身计划和营养补充剂重塑为图,目标是根据我的用户画像推荐健身计划、营养补充剂和其他用户。对于不熟悉的人来说,BeachBody负责P90X、INSANITY、T25以及多年来他们通过DVD发行的许多其他产品。
项目
在这个推荐演示中,我利用了他们现有网站上的所有公开可用数据,并创建了几个用户画像,以展示将其现有数据转换为Neo4j图数据库的个性化推荐和关联数据优势。我着重提供了以下几个关键推荐:
-
1. 哪些健身计划最适合帮助我达成我的锻炼目标?
-
2. 哪些营养补充剂将帮助我实现我的饮食和锻炼目标?
-
3. 社区中是否有其他用户可以和我一起锻炼,以及哪些锻炼适合我们一起进行?
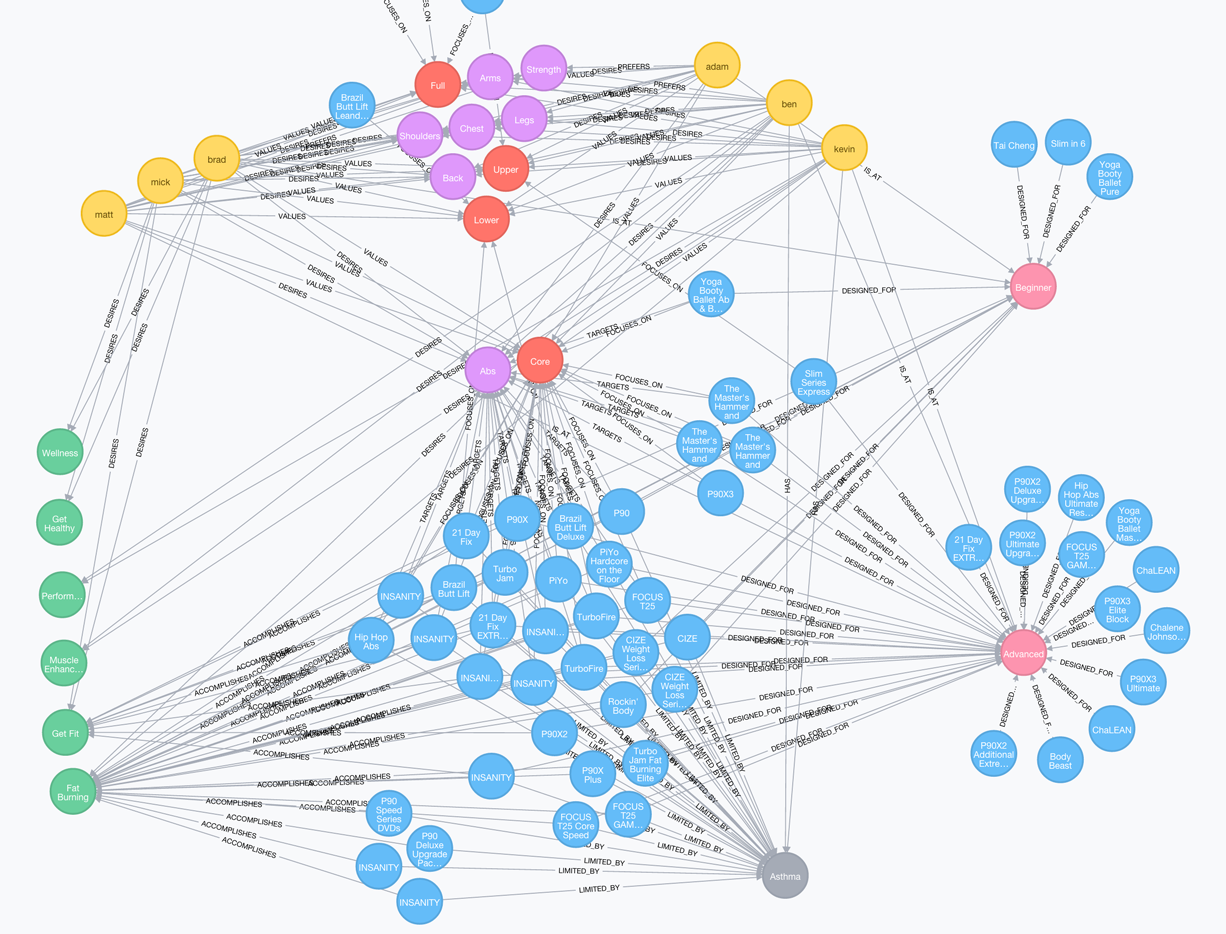
概念
网站目前主要存在的概念是健身计划、营养补充剂、装备和社区。在初步处理时,我选择忽略装备。
我认为这些已声明的概念之间能够很好地契合的主要想法,将使我作为他们产品的消费者和社区的参与者会感兴趣的推荐,包括:
-
锻炼目标
-
饮食目标
-
肌肉群
-
身体部位
-
锻炼类型
-
锻炼水平
-
补充剂类型
……在考虑健身计划时,还有一个关键因素,那就是我作为消费者可能存在的任何身体限制或饮食限制。
设置
// Create Product Categories
CREATE (:Category {name: "Best Sellers"});
CREATE (:Category {name: "Weight Loss"});
CREATE (:Category {name: "Advanced"});
CREATE (:Category {name: "Express"});
CREATE (:Category {name: "Abs/Core"});
CREATE (:Category {name: "Dance"});
CREATE (:Category {name: "Extreme Results"});
CREATE (:Category {name: "Cardio/Fat Burning"});
CREATE (:Category {name: "Getting Started"});
CREATE (:Category {name: "Specialty Programs"});
CREATE (:Category {name: "Get Fit"});
CREATE (:Category {name: "Lose Weight"});
// Create Muscle Groups
CREATE (:MuscleGroup {name: "Abs"});
CREATE (:MuscleGroup {name: "Legs"});
CREATE (:MuscleGroup {name: "Arms"});
CREATE (:MuscleGroup {name: "Back"});
CREATE (:MuscleGroup {name: "Chest"});
CREATE (:MuscleGroup {name: "Shoulders"});
// Create Body Areas
CREATE (:BodyArea {name: "Full"});
CREATE (:BodyArea {name: "Upper"});
CREATE (:BodyArea {name: "Lower"});
CREATE (:BodyArea {name: "Core"});
// Create Workout Types
CREATE (:WorkoutType {name: "Endurance"});
CREATE (:WorkoutType {name: "Strength"});
CREATE (:WorkoutType {name: "Balance"});
CREATE (:WorkoutType {name: "Flexibility"});
CREATE (:WorkoutType {name: "Full Body"});
CREATE (:WorkoutType {name: "Dance"});
CREATE (:WorkoutType {name: "Cardio"});
CREATE (:WorkoutType {name: "Express"});
// Create Workout Levels
CREATE (:WorkoutLevel {name: "Beginner"});
CREATE (:WorkoutLevel {name: "Intermediate"});
CREATE (:WorkoutLevel {name: "Advanced"});
// Create Workout Goals
CREATE (:WorkoutGoal {name: "Weight Loss"});
CREATE (:WorkoutGoal {name: "Lose Weight"});
CREATE (:WorkoutGoal {name: "Fat Burning"});
CREATE (:WorkoutGoal {name: "Get Fit"});
// Create Eating Goals
CREATE (:EatingGoal {name: "Get Healthy"});
CREATE (:EatingGoal {name: "Performance"});
CREATE (:EatingGoal {name: "Muscle Enhancement"});
CREATE (:EatingGoal {name: "Weight Loss"});
CREATE (:EatingGoal {name: "Wellness"});
// Create Supplement Types
CREATE (:SupplementType {name: "Meal Replacement"});
CREATE (:SupplementType {name: "Weight Loss"});
CREATE (:SupplementType {name: "Wellness"});
CREATE (:SupplementType {name: "Beachbody Performance"});
CREATE (:SupplementType {name: "P90X Peak Performance"});
// Create Physical Limitations
CREATE (:PhysicalLimitation {name: "Asthma"});
// Create Users
CREATE (:User {username: "ben"});
CREATE (:User {username: "brad"});
CREATE (:User {username: "adam"});
CREATE (:User {username: "mick"});
CREATE (:User {username: "matt"});
CREATE (:User {username: "kevin"});
// Connect Users
MATCH (u:User {username: "ben"}), (pl:PhysicalLimitation {name: "Asthma"}) WITH u, pl CREATE (u)-[:HAS]->(pl);
MATCH (u:User {username: "ben"}), (wl:WorkoutLevel {name: "Advanced"}) WITH u, wl CREATE (u)-[:IS_AT]->(wl);
MATCH (u:User {username: "ben"}), (wt:WorkoutType {name: "Strength"}) WITH u, wt CREATE (u)-[:PREFERS]->(wt);
MATCH (u:User {username: "ben"}), (wg:WorkoutGoal {name: "Fat Burning"}) WITH u, wg CREATE (u)-[r:DESIRES]->(wg) SET r.importance = toFloat(1.0);
MATCH (u:User {username: "ben"}), (wg:WorkoutGoal {name: "Weight Loss"}) WITH u, wg CREATE (u)-[r:DESIRES]->(wg) SET r.importance = toFloat(0.8);
MATCH (u:User {username: "ben"}), (ba:BodyArea {name: "Core"}) WITH u, ba CREATE (u)-[r:VALUES]->(ba) SET r.importance = toFloat(1.0);
MATCH (u:User {username: "ben"}), (ba:BodyArea {name: "Upper"}) WITH u, ba CREATE (u)-[r:VALUES]->(ba) SET r.importance = toFloat(0.8);
MATCH (u:User {username: "ben"}), (ba:BodyArea {name: "Full"}) WITH u, ba CREATE (u)-[r:VALUES]->(ba) SET r.importance = toFloat(0.7);
MATCH (u:User {username: "ben"}), (ba:BodyArea {name: "Lower"}) WITH u, ba CREATE (u)-[r:VALUES]->(ba) SET r.importance = toFloat(0.4);
MATCH (u:User {username: "ben"}), (mg:MuscleGroup {name: "Abs"}) WITH u, mg CREATE (u)-[r:DESIRES]->(mg) SET r.importance = toFloat(1.0);
MATCH (u:User {username: "ben"}), (mg:MuscleGroup {name: "Chest"}) WITH u, mg CREATE (u)-[r:DESIRES]->(mg) SET r.importance = toFloat(0.8);
MATCH (u:User {username: "ben"}), (mg:MuscleGroup {name: "Arms"}) WITH u, mg CREATE (u)-[r:DESIRES]->(mg) SET r.importance = toFloat(0.8);
MATCH (u:User {username: "ben"}), (mg:MuscleGroup {name: "Shoulders"}) WITH u, mg CREATE (u)-[r:DESIRES]->(mg) SET r.importance = toFloat(0.8);
MATCH (u:User {username: "ben"}), (mg:MuscleGroup {name: "Back"}) WITH u, mg CREATE (u)-[r:DESIRES]->(mg) SET r.importance = toFloat(0.6);
MATCH (u:User {username: "ben"}), (mg:MuscleGroup {name: "Legs"}) WITH u, mg CREATE (u)-[r:DESIRES]->(mg) SET r.importance = toFloat(0.2);
MATCH (u:User {username: "kevin"}), (pl:PhysicalLimitation {name: "Asthma"}) WITH u, pl CREATE (u)-[:HAS]->(pl);
MATCH (u:User {username: "kevin"}), (wl:WorkoutLevel {name: "Advanced"}) WITH u, wl CREATE (u)-[:IS_AT]->(wl);
MATCH (u:User {username: "kevin"}), (wt:WorkoutType {name: "Endurance"}) WITH u, wt CREATE (u)-[:PREFERS]->(wt);
MATCH (u:User {username: "kevin"}), (wg:WorkoutGoal {name: "Fat Burning"}) WITH u, wg CREATE (u)-[r:DESIRES]->(wg) SET r.importance = toFloat(1.0);
MATCH (u:User {username: "kevin"}), (ba:BodyArea {name: "Core"}) WITH u, ba CREATE (u)-[r:VALUES]->(ba) SET r.importance = toFloat(0.6);
MATCH (u:User {username: "kevin"}), (ba:BodyArea {name: "Upper"}) WITH u, ba CREATE (u)-[r:VALUES]->(ba) SET r.importance = toFloat(0.8);
MATCH (u:User {username: "kevin"}), (ba:BodyArea {name: "Full"}) WITH u, ba CREATE (u)-[r:VALUES]->(ba) SET r.importance = toFloat(0.7);
MATCH (u:User {username: "kevin"}), (ba:BodyArea {name: "Lower"}) WITH u, ba CREATE (u)-[r:VALUES]->(ba) SET r.importance = toFloat(0.4);
MATCH (u:User {username: "kevin"}), (mg:MuscleGroup {name: "Abs"}) WITH u, mg CREATE (u)-[r:DESIRES]->(mg) SET r.importance = toFloat(0.6);
MATCH (u:User {username: "kevin"}), (mg:MuscleGroup {name: "Chest"}) WITH u, mg CREATE (u)-[r:DESIRES]->(mg) SET r.importance = toFloat(0.8);
MATCH (u:User {username: "kevin"}), (mg:MuscleGroup {name: "Arms"}) WITH u, mg CREATE (u)-[r:DESIRES]->(mg) SET r.importance = toFloat(0.8);
MATCH (u:User {username: "kevin"}), (mg:MuscleGroup {name: "Shoulders"}) WITH u, mg CREATE (u)-[r:DESIRES]->(mg) SET r.importance = toFloat(0.8);
MATCH (u:User {username: "kevin"}), (mg:MuscleGroup {name: "Back"}) WITH u, mg CREATE (u)-[r:DESIRES]->(mg) SET r.importance = toFloat(0.6);
MATCH (u:User {username: "kevin"}), (mg:MuscleGroup {name: "Legs"}) WITH u, mg CREATE (u)-[r:DESIRES]->(mg) SET r.importance = toFloat(0.2);
MATCH (u:User {username: "brad"}), (wl:WorkoutLevel {name: "Beginner"}) WITH u, wl CREATE (u)-[:IS_AT]->(wl);
MATCH (u:User {username: "brad"}), (wt:WorkoutType {name: "Cardio"}) WITH u, wt CREATE (u)-[:PREFERS]->(wt);
MATCH (u:User {username: "brad"}), (wg:WorkoutGoal {name: "Get Fit"}) WITH u, wg CREATE (u)-[r:DESIRES]->(wg) SET r.importance = toFloat(1.0);
MATCH (u:User {username: "brad"}), (ba:BodyArea {name: "Core"}) WITH u, ba CREATE (u)-[r:VALUES]->(ba) SET r.importance = toFloat(0.6);
MATCH (u:User {username: "brad"}), (ba:BodyArea {name: "Upper"}) WITH u, ba CREATE (u)-[r:VALUES]->(ba) SET r.importance = toFloat(0.8);
MATCH (u:User {username: "brad"}), (ba:BodyArea {name: "Full"}) WITH u, ba CREATE (u)-[r:VALUES]->(ba) SET r.importance = toFloat(0.7);
MATCH (u:User {username: "brad"}), (ba:BodyArea {name: "Lower"}) WITH u, ba CREATE (u)-[r:VALUES]->(ba) SET r.importance = toFloat(0.4);
MATCH (u:User {username: "brad"}), (mg:MuscleGroup {name: "Abs"}) WITH u, mg CREATE (u)-[r:DESIRES]->(mg) SET r.importance = toFloat(0.6);
MATCH (u:User {username: "brad"}), (mg:MuscleGroup {name: "Chest"}) WITH u, mg CREATE (u)-[r:DESIRES]->(mg) SET r.importance = toFloat(0.8);
MATCH (u:User {username: "brad"}), (mg:MuscleGroup {name: "Arms"}) WITH u, mg CREATE (u)-[r:DESIRES]->(mg) SET r.importance = toFloat(0.8);
MATCH (u:User {username: "brad"}), (mg:MuscleGroup {name: "Shoulders"}) WITH u, mg CREATE (u)-[r:DESIRES]->(mg) SET r.importance = toFloat(0.8);
MATCH (u:User {username: "brad"}), (mg:MuscleGroup {name: "Back"}) WITH u, mg CREATE (u)-[r:DESIRES]->(mg) SET r.importance = toFloat(0.6);
MATCH (u:User {username: "brad"}), (mg:MuscleGroup {name: "Legs"}) WITH u, mg CREATE (u)-[r:DESIRES]->(mg) SET r.importance = toFloat(0.2);
MATCH (u:User {username: "adam"}), (wl:WorkoutLevel {name: "Beginner"}) WITH u, wl CREATE (u)-[:IS_AT]->(wl);
MATCH (u:User {username: "adam"}), (wt:WorkoutType {name: "Strength"}) WITH u, wt CREATE (u)-[:PREFERS]->(wt);
MATCH (u:User {username: "adam"}), (wg:WorkoutGoal {name: "Lose Weight"}) WITH u, wg CREATE (u)-[r:DESIRES]->(wg) SET r.importance = toFloat(1.0);
MATCH (u:User {username: "adam"}), (ba:BodyArea {name: "Core"}) WITH u, ba CREATE (u)-[r:VALUES]->(ba) SET r.importance = toFloat(0.6);
MATCH (u:User {username: "adam"}), (ba:BodyArea {name: "Upper"}) WITH u, ba CREATE (u)-[r:VALUES]->(ba) SET r.importance = toFloat(0.8);
MATCH (u:User {username: "adam"}), (ba:BodyArea {name: "Full"}) WITH u, ba CREATE (u)-[r:VALUES]->(ba) SET r.importance = toFloat(0.7);
MATCH (u:User {username: "adam"}), (ba:BodyArea {name: "Lower"}) WITH u, ba CREATE (u)-[r:VALUES]->(ba) SET r.importance = toFloat(0.4);
MATCH (u:User {username: "adam"}), (mg:MuscleGroup {name: "Abs"}) WITH u, mg CREATE (u)-[r:DESIRES]->(mg) SET r.importance = toFloat(0.6);
MATCH (u:User {username: "adam"}), (mg:MuscleGroup {name: "Chest"}) WITH u, mg CREATE (u)-[r:DESIRES]->(mg) SET r.importance = toFloat(0.8);
MATCH (u:User {username: "adam"}), (mg:MuscleGroup {name: "Arms"}) WITH u, mg CREATE (u)-[r:DESIRES]->(mg) SET r.importance = toFloat(0.8);
MATCH (u:User {username: "adam"}), (mg:MuscleGroup {name: "Shoulders"}) WITH u, mg CREATE (u)-[r:DESIRES]->(mg) SET r.importance = toFloat(0.8);
MATCH (u:User {username: "adam"}), (mg:MuscleGroup {name: "Back"}) WITH u, mg CREATE (u)-[r:DESIRES]->(mg) SET r.importance = toFloat(0.6);
MATCH (u:User {username: "adam"}), (mg:MuscleGroup {name: "Legs"}) WITH u, mg CREATE (u)-[r:DESIRES]->(mg) SET r.importance = toFloat(0.2);
MATCH (u:User {username: "mick"}), (wl:WorkoutLevel {name: "Intermediate"}) WITH u, wl CREATE (u)-[:IS_AT]->(wl);
MATCH (u:User {username: "mick"}), (wt:WorkoutType {name: "Dance"}) WITH u, wt CREATE (u)-[:PREFERS]->(wt);
MATCH (u:User {username: "mick"}), (wg:WorkoutGoal {name: "Get Fit"}) WITH u, wg CREATE (u)-[r:DESIRES]->(wg) SET r.importance = toFloat(1.0);
MATCH (u:User {username: "mick"}), (ba:BodyArea {name: "Core"}) WITH u, ba CREATE (u)-[r:VALUES]->(ba) SET r.importance = toFloat(0.6);
MATCH (u:User {username: "mick"}), (ba:BodyArea {name: "Upper"}) WITH u, ba CREATE (u)-[r:VALUES]->(ba) SET r.importance = toFloat(0.8);
MATCH (u:User {username: "mick"}), (ba:BodyArea {name: "Full"}) WITH u, ba CREATE (u)-[r:VALUES]->(ba) SET r.importance = toFloat(0.7);
MATCH (u:User {username: "mick"}), (ba:BodyArea {name: "Lower"}) WITH u, ba CREATE (u)-[r:VALUES]->(ba) SET r.importance = toFloat(0.4);
MATCH (u:User {username: "mick"}), (mg:MuscleGroup {name: "Abs"}) WITH u, mg CREATE (u)-[r:DESIRES]->(mg) SET r.importance = toFloat(0.6);
MATCH (u:User {username: "mick"}), (mg:MuscleGroup {name: "Chest"}) WITH u, mg CREATE (u)-[r:DESIRES]->(mg) SET r.importance = toFloat(0.8);
MATCH (u:User {username: "mick"}), (mg:MuscleGroup {name: "Arms"}) WITH u, mg CREATE (u)-[r:DESIRES]->(mg) SET r.importance = toFloat(0.8);
MATCH (u:User {username: "mick"}), (mg:MuscleGroup {name: "Shoulders"}) WITH u, mg CREATE (u)-[r:DESIRES]->(mg) SET r.importance = toFloat(0.8);
MATCH (u:User {username: "mick"}), (mg:MuscleGroup {name: "Back"}) WITH u, mg CREATE (u)-[r:DESIRES]->(mg) SET r.importance = toFloat(0.6);
MATCH (u:User {username: "mick"}), (mg:MuscleGroup {name: "Legs"}) WITH u, mg CREATE (u)-[r:DESIRES]->(mg) SET r.importance = toFloat(0.2);
MATCH (u:User {username: "matt"}), (wl:WorkoutLevel {name: "Advanced"}) WITH u, wl CREATE (u)-[:IS_AT]->(wl);
MATCH (u:User {username: "matt"}), (wt:WorkoutType {name: "Strength"}) WITH u, wt CREATE (u)-[:PREFERS]->(wt);
MATCH (u:User {username: "matt"}), (wg:WorkoutGoal {name: "Get Weight"}) WITH u, wg CREATE (u)-[r:DESIRES]->(wg) SET r.importance = toFloat(1.0);
MATCH (u:User {username: "matt"}), (ba:BodyArea {name: "Core"}) WITH u, ba CREATE (u)-[r:VALUES]->(ba) SET r.importance = toFloat(0.8);
MATCH (u:User {username: "matt"}), (ba:BodyArea {name: "Upper"}) WITH u, ba CREATE (u)-[r:VALUES]->(ba) SET r.importance = toFloat(1.0);
MATCH (u:User {username: "matt"}), (ba:BodyArea {name: "Full"}) WITH u, ba CREATE (u)-[r:VALUES]->(ba) SET r.importance = toFloat(0.7);
MATCH (u:User {username: "matt"}), (ba:BodyArea {name: "Lower"}) WITH u, ba CREATE (u)-[r:VALUES]->(ba) SET r.importance = toFloat(0.4);
MATCH (u:User {username: "matt"}), (mg:MuscleGroup {name: "Abs"}) WITH u, mg CREATE (u)-[r:DESIRES]->(mg) SET r.importance = toFloat(0.6);
MATCH (u:User {username: "matt"}), (mg:MuscleGroup {name: "Chest"}) WITH u, mg CREATE (u)-[r:DESIRES]->(mg) SET r.importance = toFloat(1.0);
MATCH (u:User {username: "matt"}), (mg:MuscleGroup {name: "Arms"}) WITH u, mg CREATE (u)-[r:DESIRES]->(mg) SET r.importance = toFloat(0.8);
MATCH (u:User {username: "matt"}), (mg:MuscleGroup {name: "Shoulders"}) WITH u, mg CREATE (u)-[r:DESIRES]->(mg) SET r.importance = toFloat(0.8);
MATCH (u:User {username: "matt"}), (mg:MuscleGroup {name: "Back"}) WITH u, mg CREATE (u)-[r:DESIRES]->(mg) SET r.importance = toFloat(0.6);
MATCH (u:User {username: "matt"}), (mg:MuscleGroup {name: "Legs"}) WITH u, mg CREATE (u)-[r:DESIRES]->(mg) SET r.importance = toFloat(0.2);
// Create Fitness Programs
CREATE (fp:FitnessProgram {name: "The Master's Hammer and Chisel"}) SET fp.displayName = "The Master's Hammer and Chisel™";
CREATE (fp:FitnessProgram {name: "The Master's Hammer and Chisel Deluxe Upgrade"}) SET fp.displayName = "The Master's Hammer and Chisel™ Deluxe Upgrade";
CREATE (fp:FitnessProgram {name: "The Master's Hammer and Chisel Deluxe Workouts—DVD Workout"}) SET fp.displayName = "The Master's Hammer and Chisel™ Deluxe Workouts—DVD Workout";
CREATE (fp:FitnessProgram {name: "CIZE"}) SET fp.displayName = "CIZE®";
CREATE (fp:FitnessProgram {name: "CIZE Weight Loss Series Upgrade"}) SET fp.displayName = "CIZE™ Weight Loss Series Upgrade";
CREATE (fp:FitnessProgram {name: "21 Day Fix"}) SET fp.displayName = "21 Day Fix®";
CREATE (fp:FitnessProgram {name: "CIZE Weight Loss Series DVD only"}) SET fp.displayName = "CIZE™ Weight Loss Series DVD only";
CREATE (fp:FitnessProgram {name: "Body Beast Lucky 7 – DVD WORKOUT"}) SET fp.displayName = "Body Beast® Lucky 7 – DVD WORKOUT";
CREATE (fp:FitnessProgram {name: "BODY BEAST TEMPO – DVD WORKOUT"}) SET fp.displayName = "BODY BEAST® TEMPO – DVD WORKOUT";
CREATE (fp:FitnessProgram {name: "21 Day Fix EXTREME"}) SET fp.displayName = "21 Day Fix EXTREME®";
CREATE (fp:FitnessProgram {name: "INSANITY MAX:30™"}) SET fp.displayName = "INSANITY MAX:30™";
CREATE (fp:FitnessProgram {name: "P90"}) SET fp.displayName = "P90®";
CREATE (fp:FitnessProgram {name: "FOCUS T25"}) SET fp.displayName = "FOCUS T25®";
CREATE (fp:FitnessProgram {name: "P90X3"}) SET fp.displayName = "P90X3®";
CREATE (fp:FitnessProgram {name: "PiYo"}) SET fp.displayName = "PiYo®";
CREATE (fp:FitnessProgram {name: "Tony Horton's 10-Minute Trainer"}) SET fp.displayName = "Tony Horton's 10-Minute Trainer®";
CREATE (fp:FitnessProgram {name: "21 Day Fix Ultimate DVD"}) SET fp.displayName = "21 Day Fix® Ultimate DVD";
CREATE (fp:FitnessProgram {name: "Body Beast"}) SET fp.displayName = "Body Beast®";
CREATE (fp:FitnessProgram {name: "Brazil Butt Lift"}) SET fp.displayName = "Brazil Butt Lift®";
CREATE (fp:FitnessProgram {name: "Brazil Butt Lift Leandro's Secret Weapon Workout"}) SET fp.displayName = "Brazil Butt Lift® Leandro's Secret Weapon Workout";
CREATE (fp:FitnessProgram {name: "ChaLEAN Extreme"}) SET fp.displayName = "ChaLEAN Extreme®";
CREATE (fp:FitnessProgram {name: "ChaLEAN Extreme Deluxe Upgrade"}) SET fp.displayName = "ChaLEAN Extreme® Deluxe Upgrade";
CREATE (fp:FitnessProgram {name: "Chalene Johnson's Get On the Ball!"}) SET fp.displayName = "Chalene Johnson's Get On the Ball!";
CREATE (fp:FitnessProgram {name: "Get Real with Shaun T"}) SET fp.displayName = "Get Real with Shaun T™";
CREATE (fp:FitnessProgram {name: "Hip Hop Abs"}) SET fp.displayName = "Hip Hop Abs®";
CREATE (fp:FitnessProgram {name: "Hip Hop Abs Extreme"}) SET fp.displayName = "Hip Hop Abs® Extreme";
CREATE (fp:FitnessProgram {name: "Hip Hop Abs Ultimate Results"}) SET fp.displayName = "Hip Hop Abs® Ultimate Results";
CREATE (fp:FitnessProgram {name: "INSANITY"}) SET fp.displayName = "INSANITY®";
CREATE (fp:FitnessProgram {name: "INSANITY Deluxe"}) SET fp.displayName = "INSANITY® Deluxe";
CREATE (fp:FitnessProgram {name: "INSANITY Fast and Furious"}) SET fp.displayName = "INSANITY® Fast and Furious";
CREATE (fp:FitnessProgram {name: "INSANITY Fast and Furious Abs"}) SET fp.displayName = "INSANITY® Fast and Furious Abs";
CREATE (fp:FitnessProgram {name: "INSANITY Sanity Check"}) SET fp.displayName = "INSANITY® Sanity Check";
CREATE (fp:FitnessProgram {name: "INSANITY: THE ASYLUM"}) SET fp.displayName = "INSANITY: THE ASYLUM®";
CREATE (fp:FitnessProgram {name: "INSANITY: THE ASYLUM Volume 2"}) SET fp.displayName = "INSANITY: THE ASYLUM® Volume 2";
CREATE (fp:FitnessProgram {name: "INSANITY: THE ASYLUM Volume 2 PURE CONTACT"}) SET fp.displayName = "INSANITY: THE ASYLUM® Volume 2 PURE CONTACT";
CREATE (fp:FitnessProgram {name: "P90X"}) SET fp.displayName = "P90X®";
CREATE (fp:FitnessProgram {name: "P90X2"}) SET fp.displayName = "P90X2®";
CREATE (fp:FitnessProgram {name: "P90X ONE on ONE with Tony Horton Volume 1, Full Edition"}) SET fp.displayName = "P90X ONE on ONE® with Tony Horton Volume 1, Full Edition";
CREATE (fp:FitnessProgram {name: "P90X Plus"}) SET fp.displayName = "P90X® Plus";
CREATE (fp:FitnessProgram {name: "Power Half Hour"}) SET fp.displayName = "Power Half Hour®";
CREATE (fp:FitnessProgram {name: "Rockin' Body"}) SET fp.displayName = "Rockin' Body®";
CREATE (fp:FitnessProgram {name: "Shaun T's Dance Party Series"}) SET fp.displayName = "Shaun T's Dance Party Series";
CREATE (fp:FitnessProgram {name: "Shaun T's Fit Kids Club"}) SET fp.displayName = "Shaun T's Fit Kids® Club";
CREATE (fp:FitnessProgram {name: "Slim in 6"}) SET fp.displayName = "Slim in 6®";
CREATE (fp:FitnessProgram {name: "Slim Series"}) SET fp.displayName = "Slim Series®";
CREATE (fp:FitnessProgram {name: "Slim Series Express"}) SET fp.displayName = "Slim Series® Express";
CREATE (fp:FitnessProgram {name: "Keep It Up!"}) SET fp.displayName = "Keep It Up!";
CREATE (fp:FitnessProgram {name: "Tai Cheng"}) SET fp.displayName = "Tai Cheng®";
CREATE (fp:FitnessProgram {name: "TurboFire"}) SET fp.displayName = "TurboFire®";
CREATE (fp:FitnessProgram {name: "TurboFire Advanced Classes"}) SET fp.displayName = "TurboFire® Advanced Classes";
CREATE (fp:FitnessProgram {name: "TurboFire Fire Starter Pack"}) SET fp.displayName = "TurboFire® Fire Starter Pack";
CREATE (fp:FitnessProgram {name: "TurboFire Keep on Burnin' DVD"}) SET fp.displayName = "TurboFire® Keep on Burnin' DVD";
CREATE (fp:FitnessProgram {name: "Turbo Jam"}) SET fp.displayName = "Turbo Jam®";
CREATE (fp:FitnessProgram {name: "Turbo Jam Fat Burning Elite"}) SET fp.displayName = "Turbo Jam® Fat Burning Elite";
CREATE (fp:FitnessProgram {name: "Turbo Jam LIVE!"}) SET fp.displayName = "Turbo Jam® LIVE!";
CREATE (fp:FitnessProgram {name: "Total Body Solution"}) SET fp.displayName = "Total Body Solution®";
CREATE (fp:FitnessProgram {name: "Yoga Booty Ballet Ab & Butt Makeover"}) SET fp.displayName = "Yoga Booty Ballet® Ab & Butt Makeover";
CREATE (fp:FitnessProgram {name: "Yoga Booty Ballet Baby On the Way"}) SET fp.displayName = "Yoga Booty Ballet® Baby On the Way";
CREATE (fp:FitnessProgram {name: "Yoga Booty Ballet Master Series"}) SET fp.displayName = "Yoga Booty Ballet® Master Series";
CREATE (fp:FitnessProgram {name: "Yoga Booty Ballet Pure & Simple Yoga"}) SET fp.displayName = "Yoga Booty Ballet® Pure & Simple Yoga";
CREATE (fp:FitnessProgram {name: "INSANITY MAX:30 Deluxe DVDs"}) SET fp.displayName = "INSANITY MAX:30™ Deluxe DVDs";
// Create Additional Fitness Programs not in All set
CREATE (fp:FitnessProgram {name: "PiYo Hardcore on the Floor DVD"}) SET fp.displayName = "PiYo® Hardcore on the Floor DVD";
CREATE (fp:FitnessProgram {name: "P90 Deluxe Upgrade Package"}) SET fp.displayName = "P90® Deluxe Upgrade Package";
CREATE (fp:FitnessProgram {name: "P90 Speed Series DVDs"}) SET fp.displayName = "P90® Speed Series DVDs";
CREATE (fp:FitnessProgram {name: "21 Day Fix Plyo Fix DVD"}) SET fp.displayName = "21 Day Fix® Plyo Fix DVD";
CREATE (fp:FitnessProgram {name: "PiYo Strength DVD"}) SET fp.displayName = "PiYo® Strength® DVD";
CREATE (fp:FitnessProgram {name: "Brazil Butt Lift Deluxe"}) SET fp.displayName = "Brazil Butt Lift® Deluxe";
CREATE (fp:FitnessProgram {name: "P90X3 Elite Block Workouts"}) SET fp.displayName = "P90X3® Elite Block Workouts";
CREATE (fp:FitnessProgram {name: "21 Day Fix EXTREME Ultimate Upgrade - DVD Workout"}) SET fp.displayName = "21 Day Fix EXTREME® Ultimate Upgrade - DVD Workout";
CREATE (fp:FitnessProgram {name: "FOCUS T25 GAMMA Deluxe"}) SET fp.displayName = "FOCUS T25® GAMMA Deluxe";
CREATE (fp:FitnessProgram {name: "FOCUS T25 GAMMA Cycle DVDs"}) SET fp.displayName = "FOCUS T25® GAMMA Cycle DVDs";
CREATE (fp:FitnessProgram {name: "FOCUS T25 Core Speed"}) SET fp.displayName = "FOCUS T25® Core Speed";
CREATE (fp:FitnessProgram {name: "P90X2 Ultimate Upgrade Kit"}) SET fp.displayName = "P90X2® Ultimate Upgrade Kit";
CREATE (fp:FitnessProgram {name: "P90X2 Deluxe Upgrade Kit"}) SET fp.displayName = "P90X2® Deluxe Upgrade Kit";
CREATE (fp:FitnessProgram {name: "P90X2 Additional Extreme Workouts"}) SET fp.displayName = "P90X2® Additional Extreme Workouts";
CREATE (fp:FitnessProgram {name: "P90X3 Ultimate"}) SET fp.displayName = "P90X3® Ultimate";
CREATE (fp:FitnessProgram {name: "INSANITY MAX:30 Ab Maximizer Kit"}) SET fp.displayName = "INSANITY MAX:30™ Ab Maximizer Kit";
CREATE (fp:FitnessProgram {name: "P90X One on One Volume 3, Full Edition"}) SET fp.displayName = "P90X One on One® Volume 3, Full Edition";
// Connect Workout Goals to Fitness Programs
MATCH (wg:WorkoutGoal {name: "Weight Loss"}), (fp:FitnessProgram {name: "The Master's Hammer and Chisel"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Weight Loss"}), (fp:FitnessProgram {name: "PiYo"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Weight Loss"}), (fp:FitnessProgram {name: "The Master's Hammer and Chisel Deluxe Upgrade"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Weight Loss"}), (fp:FitnessProgram {name: "The Master's Hammer and Chisel Deluxe Workouts—DVD Workout"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Weight Loss"}), (fp:FitnessProgram {name: "CIZE"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Weight Loss"}), (fp:FitnessProgram {name: "21 Day Fix"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Weight Loss"}), (fp:FitnessProgram {name: "FOCUS T25"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Weight Loss"}), (fp:FitnessProgram {name: "21 Day Fix EXTREME"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Weight Loss"}), (fp:FitnessProgram {name: "P90X3"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Weight Loss"}), (fp:FitnessProgram {name: "CIZE Weight Loss Series Upgrade"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Weight Loss"}), (fp:FitnessProgram {name: "CIZE Weight Loss Series DVD only"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Weight Loss"}), (fp:FitnessProgram {name: "PiYo Hardcore on the Floor DVD"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Weight Loss"}), (fp:FitnessProgram {name: "P90"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Weight Loss"}), (fp:FitnessProgram {name: "P90 Deluxe Upgrade Package"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Weight Loss"}), (fp:FitnessProgram {name: "P90 Speed Series DVDs"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Weight Loss"}), (fp:FitnessProgram {name: "21 Day Fix Plyo Fix DVD"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Weight Loss"}), (fp:FitnessProgram {name: "21 Day Fix Ultimate DVD"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Weight Loss"}), (fp:FitnessProgram {name: "Rockin' Body"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Weight Loss"}), (fp:FitnessProgram {name: "PiYo Strength DVD"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Weight Loss"}), (fp:FitnessProgram {name: "Turbo Jam"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Weight Loss"}), (fp:FitnessProgram {name: "TurboFire"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Weight Loss"}), (fp:FitnessProgram {name: "TurboFire Advanced Classes"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Weight Loss"}), (fp:FitnessProgram {name: "Brazil Butt Lift"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Weight Loss"}), (fp:FitnessProgram {name: "Slim in 6"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Weight Loss"}), (fp:FitnessProgram {name: "Hip Hop Abs"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Weight Loss"}), (fp:FitnessProgram {name: "Brazil Butt Lift Deluxe"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Lose Weight"}), (fp:FitnessProgram {name: "21 Day Fix"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Lose Weight"}), (fp:FitnessProgram {name: "21 Day Fix EXTREME"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Lose Weight"}), (fp:FitnessProgram {name: "Turbo Jam"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Lose Weight"}), (fp:FitnessProgram {name: "TurboFire"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Lose Weight"}), (fp:FitnessProgram {name: "Brazil Butt Lift"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Lose Weight"}), (fp:FitnessProgram {name: "P90X"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Lose Weight"}), (fp:FitnessProgram {name: "INSANITY"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Lose Weight"}), (fp:FitnessProgram {name: "Hip Hop Abs"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Lose Weight"}), (fp:FitnessProgram {name: "Slim in 6"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Lose Weight"}), (fp:FitnessProgram {name: "PiYo"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Get Fit"}), (fp:FitnessProgram {name: "21 Day Fix"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Get Fit"}), (fp:FitnessProgram {name: "21 Day Fix EXTREME"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Get Fit"}), (fp:FitnessProgram {name: "INSANITY"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Get Fit"}), (fp:FitnessProgram {name: "Hip Hop Abs"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Get Fit"}), (fp:FitnessProgram {name: "Brazil Butt Lift"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Get Fit"}), (fp:FitnessProgram {name: "Turbo Jam"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Get Fit"}), (fp:FitnessProgram {name: "INSANITY: THE ASYLUM"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Get Fit"}), (fp:FitnessProgram {name: "P90X"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Get Fit"}), (fp:FitnessProgram {name: "P90X2"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Fat Burning"}), (fp:FitnessProgram {name: "CIZE"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Fat Burning"}), (fp:FitnessProgram {name: "21 Day Fix"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Fat Burning"}), (fp:FitnessProgram {name: "INSANITY MAX:30"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Fat Burning"}), (fp:FitnessProgram {name: "FOCUS T25"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Fat Burning"}), (fp:FitnessProgram {name: "21 Day Fix EXTREME"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Fat Burning"}), (fp:FitnessProgram {name: "PiYo"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Fat Burning"}), (fp:FitnessProgram {name: "CIZE Weight Loss Series Upgrade"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Fat Burning"}), (fp:FitnessProgram {name: "CIZE Weight Loss Series DVD only"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Fat Burning"}), (fp:FitnessProgram {name: "P90"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Fat Burning"}), (fp:FitnessProgram {name: "INSANITY MAX:30 Ab Maximizer Kit"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Fat Burning"}), (fp:FitnessProgram {name: "Rockin' Body"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Fat Burning"}), (fp:FitnessProgram {name: "INSANITY"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Fat Burning"}), (fp:FitnessProgram {name: "P90 Deluxe Upgrade Package"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Fat Burning"}), (fp:FitnessProgram {name: "P90 Speed Series DVDs"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Fat Burning"}), (fp:FitnessProgram {name: "PiYo Strength® DVD"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Fat Burning"}), (fp:FitnessProgram {name: "PiYo Hardcore on the Floor DVD"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Fat Burning"}), (fp:FitnessProgram {name: "TurboFire"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Fat Burning"}), (fp:FitnessProgram {name: "TurboFire Advanced Classes"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Fat Burning"}), (fp:FitnessProgram {name: "INSANITY: THE ASYLUM"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Fat Burning"}), (fp:FitnessProgram {name: "INSANITY: THE ASYLUM Volume 2"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Fat Burning"}), (fp:FitnessProgram {name: "Hip Hop Abs"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Fat Burning"}), (fp:FitnessProgram {name: "Turbo Jam"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Fat Burning"}), (fp:FitnessProgram {name: "Brazil Butt Lift"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Fat Burning"}), (fp:FitnessProgram {name: "P90X Plus"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Fat Burning"}), (fp:FitnessProgram {name: "Turbo Jam Fat Burning Elite"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Fat Burning"}), (fp:FitnessProgram {name: "INSANITY Deluxe"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Fat Burning"}), (fp:FitnessProgram {name: "INSANITY Fast and Furious"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Fat Burning"}), (fp:FitnessProgram {name: "INSANITY Sanity Check"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Fat Burning"}), (fp:FitnessProgram {name: "INSANITY Fast and Furious Abs"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Fat Burning"}), (fp:FitnessProgram {name: "Brazil Butt Lift Deluxe"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Fat Burning"}), (fp:FitnessProgram {name: "FOCUS T25 GAMMA Deluxe"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
MATCH (wg:WorkoutGoal {name: "Fat Burning"}), (fp:FitnessProgram {name: "FOCUS T25 Core Speed"}) WITH wg, fp CREATE (fp)-[:ACCOMPLISHES]->(wg);
// Connect Workout Levels to Fitness Programs
MATCH (wl:WorkoutLevel {name: "Beginner"}), (fp:FitnessProgram {name: "CIZE"}) WITH wl, fp CREATE (fp)-[:DESIGNED_FOR]->(wl);
MATCH (wl:WorkoutLevel {name: "Beginner"}), (fp:FitnessProgram {name: "Rockin' Body"}) WITH wl, fp CREATE (fp)-[:DESIGNED_FOR]->(wl);
MATCH (wl:WorkoutLevel {name: "Beginner"}), (fp:FitnessProgram {name: "21 Day Fix"}) WITH wl, fp CREATE (fp)-[:DESIGNED_FOR]->(wl);
MATCH (wl:WorkoutLevel {name: "Beginner"}), (fp:FitnessProgram {name: "P90"}) WITH wl, fp CREATE (fp)-[:DESIGNED_FOR]->(wl);
MATCH (wl:WorkoutLevel {name: "Beginner"}), (fp:FitnessProgram {name: "Brazil Butt Lift"}) WITH wl, fp CREATE (fp)-[:DESIGNED_FOR]->(wl);
MATCH (wl:WorkoutLevel {name: "Beginner"}), (fp:FitnessProgram {name: "CIZE Weight Loss Series Upgrade"}) WITH wl, fp CREATE (fp)-[:DESIGNED_FOR]->(wl);
MATCH (wl:WorkoutLevel {name: "Beginner"}), (fp:FitnessProgram {name: "CIZE Weight Loss Series DVD only"}) WITH wl, fp CREATE (fp)-[:DESIGNED_FOR]->(wl);
MATCH (wl:WorkoutLevel {name: "Beginner"}), (fp:FitnessProgram {name: "Slim in 6"}) WITH wl, fp CREATE (fp)-[:DESIGNED_FOR]->(wl);
MATCH (wl:WorkoutLevel {name: "Beginner"}), (fp:FitnessProgram {name: "Tai Cheng"}) WITH wl, fp CREATE (fp)-[:DESIGNED_FOR]->(wl);
MATCH (wl:WorkoutLevel {name: "Beginner"}), (fp:FitnessProgram {name: "Yoga Booty Ballet Pure & Simple Yoga"}) WITH wl, fp CREATE (fp)-[:DESIGNED_FOR]->(wl);
MATCH (wl:WorkoutLevel {name: "Beginner"}), (fp:FitnessProgram {name: "Yoga Booty Ballet Ab & Butt Makeover"}) WITH wl, fp CREATE (fp)-[:DESIGNED_FOR]->(wl);
MATCH (wl:WorkoutLevel {name: "Beginner"}), (fp:FitnessProgram {name: "Turbo Jam"}) WITH wl, fp CREATE (fp)-[:DESIGNED_FOR]->(wl);
MATCH (wl:WorkoutLevel {name: "Beginner"}), (fp:FitnessProgram {name: "Brazil Butt Lift Deluxe"}) WITH wl, fp CREATE (fp)-[:DESIGNED_FOR]->(wl);
MATCH (wl:WorkoutLevel {name: "Advanced"}), (fp:FitnessProgram {name: "The Master's Hammer and Chisel"}) WITH wl, fp CREATE (fp)-[:DESIGNED_FOR]->(wl);
MATCH (wl:WorkoutLevel {name: "Advanced"}), (fp:FitnessProgram {name: "21 Day Fix EXTREME"}) WITH wl, fp CREATE (fp)-[:DESIGNED_FOR]->(wl);
MATCH (wl:WorkoutLevel {name: "Advanced"}), (fp:FitnessProgram {name: "The Master's Hammer and Chisel Deluxe Upgrade"}) WITH wl, fp CREATE (fp)-[:DESIGNED_FOR]->(wl);
MATCH (wl:WorkoutLevel {name: "Advanced"}), (fp:FitnessProgram {name: "The Master's Hammer and Chisel Deluxe Workouts—DVD Workout"}) WITH wl, fp CREATE (fp)-[:DESIGNED_FOR]->(wl);
MATCH (wl:WorkoutLevel {name: "Advanced"}), (fp:FitnessProgram {name: "P90X3"}) WITH wl, fp CREATE (fp)-[:DESIGNED_FOR]->(wl);
MATCH (wl:WorkoutLevel {name: "Advanced"}), (fp:FitnessProgram {name: "P90X3 Elite Block Workouts"}) WITH wl, fp CREATE (fp)-[:DESIGNED_FOR]->(wl);
MATCH (wl:WorkoutLevel {name: "Advanced"}), (fp:FitnessProgram {name: "PiYo"}) WITH wl, fp CREATE (fp)-[:DESIGNED_FOR]->(wl);
MATCH (wl:WorkoutLevel {name: "Advanced"}), (fp:FitnessProgram {name: "INSANITY MAX:30"}) WITH wl, fp CREATE (fp)-[:DESIGNED_FOR]->(wl);
MATCH (wl:WorkoutLevel {name: "Advanced"}), (fp:FitnessProgram {name: "21 Day Fix EXTREME Ultimate Upgrade - DVD Workout"}) WITH wl, fp CREATE (fp)-[:DESIGNED_FOR]->(wl);
MATCH (wl:WorkoutLevel {name: "Advanced"}), (fp:FitnessProgram {name: "P90X"}) WITH wl, fp CREATE (fp)-[:DESIGNED_FOR]->(wl);
MATCH (wl:WorkoutLevel {name: "Advanced"}), (fp:FitnessProgram {name: "P90X2"}) WITH wl, fp CREATE (fp)-[:DESIGNED_FOR]->(wl);
MATCH (wl:WorkoutLevel {name: "Advanced"}), (fp:FitnessProgram {name: "INSANITY"}) WITH wl, fp CREATE (fp)-[:DESIGNED_FOR]->(wl);
MATCH (wl:WorkoutLevel {name: "Advanced"}), (fp:FitnessProgram {name: "FOCUS T25"}) WITH wl, fp CREATE (fp)-[:DESIGNED_FOR]->(wl);
MATCH (wl:WorkoutLevel {name: "Advanced"}), (fp:FitnessProgram {name: "FOCUS T25 GAMMA Deluxe"}) WITH wl, fp CREATE (fp)-[:DESIGNED_FOR]->(wl);
MATCH (wl:WorkoutLevel {name: "Advanced"}), (fp:FitnessProgram {name: "FOCUS T25 GAMMA Cycle DVDs"}) WITH wl, fp CREATE (fp)-[:DESIGNED_FOR]->(wl);
MATCH (wl:WorkoutLevel {name: "Advanced"}), (fp:FitnessProgram {name: "FOCUS T25 Core Speed"}) WITH wl, fp CREATE (fp)-[:DESIGNED_FOR]->(wl);
MATCH (wl:WorkoutLevel {name: "Advanced"}), (fp:FitnessProgram {name: "PiYo Strength® DVD"}) WITH wl, fp CREATE (fp)-[:DESIGNED_FOR]->(wl);
MATCH (wl:WorkoutLevel {name: "Advanced"}), (fp:FitnessProgram {name: "PiYo Hardcore on the Floor DVD"}) WITH wl, fp CREATE (fp)-[:DESIGNED_FOR]->(wl);
MATCH (wl:WorkoutLevel {name: "Advanced"}), (fp:FitnessProgram {name: "P90X2 Ultimate Upgrade Kit"}) WITH wl, fp CREATE (fp)-[:DESIGNED_FOR]->(wl);
MATCH (wl:WorkoutLevel {name: "Advanced"}), (fp:FitnessProgram {name: "P90X2 Deluxe Upgrade Kit"}) WITH wl, fp CREATE (fp)-[:DESIGNED_FOR]->(wl);
MATCH (wl:WorkoutLevel {name: "Advanced"}), (fp:FitnessProgram {name: "P90X2 Additional Extreme Workouts"}) WITH wl, fp CREATE (fp)-[:DESIGNED_FOR]->(wl);
MATCH (wl:WorkoutLevel {name: "Advanced"}), (fp:FitnessProgram {name: "ChaLEAN Extreme Deluxe Upgrade"}) WITH wl, fp CREATE (fp)-[:DESIGNED_FOR]->(wl);
MATCH (wl:WorkoutLevel {name: "Advanced"}), (fp:FitnessProgram {name: "Body Beast"}) WITH wl, fp CREATE (fp)-[:DESIGNED_FOR]->(wl);
MATCH (wl:WorkoutLevel {name: "Advanced"}), (fp:FitnessProgram {name: "TurboFire"}) WITH wl, fp CREATE (fp)-[:DESIGNED_FOR]->(wl);
MATCH (wl:WorkoutLevel {name: "Advanced"}), (fp:FitnessProgram {name: "TurboFire Advanced Classes"}) WITH wl, fp CREATE (fp)-[:DESIGNED_FOR]->(wl);
MATCH (wl:WorkoutLevel {name: "Advanced"}), (fp:FitnessProgram {name: "P90X Plus"}) WITH wl, fp CREATE (fp)-[:DESIGNED_FOR]->(wl);
MATCH (wl:WorkoutLevel {name: "Advanced"}), (fp:FitnessProgram {name: "INSANITY: THE ASYLUM"}) WITH wl, fp CREATE (fp)-[:DESIGNED_FOR]->(wl);
MATCH (wl:WorkoutLevel {name: "Advanced"}), (fp:FitnessProgram {name: "INSANITY: THE ASYLUM Volume 2"}) WITH wl, fp CREATE (fp)-[:DESIGNED_FOR]->(wl);
MATCH (wl:WorkoutLevel {name: "Advanced"}), (fp:FitnessProgram {name: "ChaLEAN Extreme"}) WITH wl, fp CREATE (fp)-[:DESIGNED_FOR]->(wl);
MATCH (wl:WorkoutLevel {name: "Advanced"}), (fp:FitnessProgram {name: "Hip Hop Abs Ultimate Results"}) WITH wl, fp CREATE (fp)-[:DESIGNED_FOR]->(wl);
MATCH (wl:WorkoutLevel {name: "Advanced"}), (fp:FitnessProgram {name: "Turbo Jam Fat Burning Elite"}) WITH wl, fp CREATE (fp)-[:DESIGNED_FOR]->(wl);
MATCH (wl:WorkoutLevel {name: "Advanced"}), (fp:FitnessProgram {name: "Yoga Booty Ballet Master Series"}) WITH wl, fp CREATE (fp)-[:DESIGNED_FOR]->(wl);
MATCH (wl:WorkoutLevel {name: "Advanced"}), (fp:FitnessProgram {name: "INSANITY Deluxe"}) WITH wl, fp CREATE (fp)-[:DESIGNED_FOR]->(wl);
MATCH (wl:WorkoutLevel {name: "Advanced"}), (fp:FitnessProgram {name: "Chalene Johnson's Get On the Ball!"}) WITH wl, fp CREATE (fp)-[:DESIGNED_FOR]->(wl);
MATCH (wl:WorkoutLevel {name: "Advanced"}), (fp:FitnessProgram {name: "Slim Series Express"}) WITH wl, fp CREATE (fp)-[:DESIGNED_FOR]->(wl);
MATCH (wl:WorkoutLevel {name: "Advanced"}), (fp:FitnessProgram {name: "P90X3 Ultimate"}) WITH wl, fp CREATE (fp)-[:DESIGNED_FOR]->(wl);
// Connect Body Areas to Fitness Programs
MATCH (ba:BodyArea {name: "Core"}), (fp:FitnessProgram {name: "The Master's Hammer and Chisel"}) WITH ba, fp CREATE (fp)-[:FOCUSES_ON]->(ba);
MATCH (ba:BodyArea {name: "Core"}), (fp:FitnessProgram {name: "PiYo Hardcore on the Floor DVD"}) WITH ba, fp CREATE (fp)-[:FOCUSES_ON]->(ba);
MATCH (ba:BodyArea {name: "Core"}), (fp:FitnessProgram {name: "The Master's Hammer and Chisel Deluxe Upgrade"}) WITH ba, fp CREATE (fp)-[:FOCUSES_ON]->(ba);
MATCH (ba:BodyArea {name: "Core"}), (fp:FitnessProgram {name: "The Master's Hammer and Chisel Deluxe Workouts—DVD Workout"}) WITH ba, fp CREATE (fp)-[:FOCUSES_ON]->(ba);
MATCH (ba:BodyArea {name: "Core"}), (fp:FitnessProgram {name: "21 Day Fix EXTREME"}) WITH ba, fp CREATE (fp)-[:FOCUSES_ON]->(ba);
MATCH (ba:BodyArea {name: "Core"}), (fp:FitnessProgram {name: "INSANITY MAX:30"}) WITH ba, fp CREATE (fp)-[:FOCUSES_ON]->(ba);
MATCH (ba:BodyArea {name: "Core"}), (fp:FitnessProgram {name: "21 Day Fix"}) WITH ba, fp CREATE (fp)-[:FOCUSES_ON]->(ba);
MATCH (ba:BodyArea {name: "Core"}), (fp:FitnessProgram {name: "FOCUS T25"}) WITH ba, fp CREATE (fp)-[:FOCUSES_ON]->(ba);
MATCH (ba:BodyArea {name: "Core"}), (fp:FitnessProgram {name: "P90X3"}) WITH ba, fp CREATE (fp)-[:FOCUSES_ON]->(ba);
MATCH (ba:BodyArea {name: "Core"}), (fp:FitnessProgram {name: "PiYo"}) WITH ba, fp CREATE (fp)-[:FOCUSES_ON]->(ba);
MATCH (ba:BodyArea {name: "Core"}), (fp:FitnessProgram {name: "INSANITY MAX:30 Ab Maximizer Kit"}) WITH ba, fp CREATE (fp)-[:FOCUSES_ON]->(ba);
MATCH (ba:BodyArea {name: "Core"}), (fp:FitnessProgram {name: "PiYo Strength® DVD"}) WITH ba, fp CREATE (fp)-[:FOCUSES_ON]->(ba);
MATCH (ba:BodyArea {name: "Core"}), (fp:FitnessProgram {name: "P90"}) WITH ba, fp CREATE (fp)-[:FOCUSES_ON]->(ba);
MATCH (ba:BodyArea {name: "Core"}), (fp:FitnessProgram {name: "TurboFire"}) WITH ba, fp CREATE (fp)-[:FOCUSES_ON]->(ba);
MATCH (ba:BodyArea {name: "Core"}), (fp:FitnessProgram {name: "TurboFire Advanced Classes"}) WITH ba, fp CREATE (fp)-[:FOCUSES_ON]->(ba);
MATCH (ba:BodyArea {name: "Core"}), (fp:FitnessProgram {name: "P90X"}) WITH ba, fp CREATE (fp)-[:FOCUSES_ON]->(ba);
MATCH (ba:BodyArea {name: "Core"}), (fp:FitnessProgram {name: "Hip Hop Abs"}) WITH ba, fp CREATE (fp)-[:FOCUSES_ON]->(ba);
MATCH (ba:BodyArea {name: "Core"}), (fp:FitnessProgram {name: "Turbo Jam"}) WITH ba, fp CREATE (fp)-[:FOCUSES_ON]->(ba);
MATCH (ba:BodyArea {name: "Core"}), (fp:FitnessProgram {name: "Yoga Booty Ballet Ab & Butt Makeover"}) WITH ba, fp CREATE (fp)-[:FOCUSES_ON]->(ba);
MATCH (ba:BodyArea {name: "Core"}), (fp:FitnessProgram {name: "INSANITY: THE ASYLUM"}) WITH ba, fp CREATE (fp)-[:FOCUSES_ON]->(ba);
MATCH (ba:BodyArea {name: "Core"}), (fp:FitnessProgram {name: "INSANITY: THE ASYLUM Volume 2"}) WITH ba, fp CREATE (fp)-[:FOCUSES_ON]->(ba);
MATCH (ba:BodyArea {name: "Core"}), (fp:FitnessProgram {name: "INSANITY Deluxe"}) WITH ba, fp CREATE (fp)-[:FOCUSES_ON]->(ba);
MATCH (ba:BodyArea {name: "Core"}), (fp:FitnessProgram {name: "INSANITY Fast and Furious Abs"}) WITH ba, fp CREATE (fp)-[:FOCUSES_ON]->(ba);
MATCH (ba:BodyArea {name: "Upper"}), (fp:FitnessProgram {name: "Slim Series"}) WITH ba, fp CREATE (fp)-[:FOCUSES_ON]->(ba);
MATCH (ba:BodyArea {name: "Upper"}), (fp:FitnessProgram {name: "Slim Series Express"}) WITH ba, fp CREATE (fp)-[:FOCUSES_ON]->(ba);
MATCH (ba:BodyArea {name: "Lower"}), (fp:FitnessProgram {name: "Brazil Butt Lift"}) WITH ba, fp CREATE (fp)-[:FOCUSES_ON]->(ba);
MATCH (ba:BodyArea {name: "Lower"}), (fp:FitnessProgram {name: "Brazil Butt Lift Deluxe"}) WITH ba, fp CREATE (fp)-[:FOCUSES_ON]->(ba);
MATCH (ba:BodyArea {name: "Lower"}), (fp:FitnessProgram {name: "Brazil Butt Lift Leandro's Secret Weapon Workout"}) WITH ba, fp CREATE (fp)-[:FOCUSES_ON]->(ba);
MATCH (ba:BodyArea {name: "Full"}), (fp:FitnessProgram {name: "Slim Series"}) WITH ba, fp CREATE (fp)-[:FOCUSES_ON]->(ba);
MATCH (ba:BodyArea {name: "Full"}), (fp:FitnessProgram {name: "P90X ONE on ONE with Tony Horton Volume 1, Full Edition"}) WITH ba, fp CREATE (fp)-[:FOCUSES_ON]->(ba);
MATCH (ba:BodyArea {name: "Full"}), (fp:FitnessProgram {name: "P90X One on One Volume 3, Full Edition"}) WITH ba, fp CREATE (fp)-[:FOCUSES_ON]->(ba);
// Connect Workout Types to Fintess Programs
MATCH (wt:WorkoutType {name: "Full Body"}), (fp:FitnessProgram {name: "Slim Series"}) WITH wt, fp CREATE (fp)-[:INVOLVES]->(wt);
MATCH (wt:WorkoutType {name: "Full Body"}), (fp:FitnessProgram {name: "P90X ONE on ONE with Tony Horton Volume 1, Full Edition"}) WITH wt, fp CREATE (fp)-[:INVOLVES]->(wt);
MATCH (wt:WorkoutType {name: "Full Body"}), (fp:FitnessProgram {name: "P90X One on One Volume 3, Full Edition"}) WITH wt, fp CREATE (fp)-[:INVOLVES]->(wt);
MATCH (wt:WorkoutType {name: "Dance"}), (fp:FitnessProgram {name: "CIZE"}) WITH wt, fp CREATE (fp)-[:INVOLVES]->(wt);
MATCH (wt:WorkoutType {name: "Dance"}), (fp:FitnessProgram {name: "Rockin' Body"}) WITH wt, fp CREATE (fp)-[:INVOLVES]->(wt);
MATCH (wt:WorkoutType {name: "Dance"}), (fp:FitnessProgram {name: "Turbo Jam LIVE!"}) WITH wt, fp CREATE (fp)-[:INVOLVES]->(wt);
MATCH (wt:WorkoutType {name: "Dance"}), (fp:FitnessProgram {name: "Hip Hop Abs"}) WITH wt, fp CREATE (fp)-[:INVOLVES]->(wt);
MATCH (wt:WorkoutType {name: "Dance"}), (fp:FitnessProgram {name: "Brazil Butt Lift"}) WITH wt, fp CREATE (fp)-[:INVOLVES]->(wt);
MATCH (wt:WorkoutType {name: "Dance"}), (fp:FitnessProgram {name: "CIZE Weight Loss Series DVD only Weight Loss Series Upgrade"}) WITH wt, fp CREATE (fp)-[:INVOLVES]->(wt);
MATCH (wt:WorkoutType {name: "Dance"}), (fp:FitnessProgram {name: "Shaun T's Dance Party Series"}) WITH wt, fp CREATE (fp)-[:INVOLVES]->(wt);
MATCH (wt:WorkoutType {name: "Dance"}), (fp:FitnessProgram {name: "Hip Hop Abs Ultimate Results"}) WITH wt, fp CREATE (fp)-[:INVOLVES]->(wt);
MATCH (wt:WorkoutType {name: "Dance"}), (fp:FitnessProgram {name: "Yoga Booty Ballet Ab & Butt Makeover"}) WITH wt, fp CREATE (fp)-[:INVOLVES]->(wt);
MATCH (wt:WorkoutType {name: "Dance"}), (fp:FitnessProgram {name: "Brazil Butt Lift Deluxe"}) WITH wt, fp CREATE (fp)-[:INVOLVES]->(wt);
MATCH (wt:WorkoutType {name: "Cardio"}), (fp:FitnessProgram {name: "CIZE"}) WITH wt, fp CREATE (fp)-[:INVOLVES]->(wt);
MATCH (wt:WorkoutType {name: "Cardio"}), (fp:FitnessProgram {name: "21 Day Fix"}) WITH wt, fp CREATE (fp)-[:INVOLVES]->(wt);
MATCH (wt:WorkoutType {name: "Cardio"}), (fp:FitnessProgram {name: "INSANITY MAX:30"}) WITH wt, fp CREATE (fp)-[:INVOLVES]->(wt);
MATCH (wt:WorkoutType {name: "Cardio"}), (fp:FitnessProgram {name: "FOCUS T25"}) WITH wt, fp CREATE (fp)-[:INVOLVES]->(wt);
MATCH (wt:WorkoutType {name: "Cardio"}), (fp:FitnessProgram {name: "21 Day Fix EXTREME"}) WITH wt, fp CREATE (fp)-[:INVOLVES]->(wt);
MATCH (wt:WorkoutType {name: "Cardio"}), (fp:FitnessProgram {name: "PiYo"}) WITH wt, fp CREATE (fp)-[:INVOLVES]->(wt);
MATCH (wt:WorkoutType {name: "Cardio"}), (fp:FitnessProgram {name: "CIZE Weight Loss Series Upgrade"}) WITH wt, fp CREATE (fp)-[:INVOLVES]->(wt);
MATCH (wt:WorkoutType {name: "Cardio"}), (fp:FitnessProgram {name: "CIZE Weight Loss Series DVD only"}) WITH wt, fp CREATE (fp)-[:INVOLVES]->(wt);
MATCH (wt:WorkoutType {name: "Cardio"}), (fp:FitnessProgram {name: "P90"}) WITH wt, fp CREATE (fp)-[:INVOLVES]->(wt);
MATCH (wt:WorkoutType {name: "Cardio"}), (fp:FitnessProgram {name: "INSANITY MAX:30 Ab Maximizer Kit"}) WITH wt, fp CREATE (fp)-[:INVOLVES]->(wt);
MATCH (wt:WorkoutType {name: "Cardio"}), (fp:FitnessProgram {name: "Rockin' Body"}) WITH wt, fp CREATE (fp)-[:INVOLVES]->(wt);
MATCH (wt:WorkoutType {name: "Cardio"}), (fp:FitnessProgram {name: "INSANITY"}) WITH wt, fp CREATE (fp)-[:INVOLVES]->(wt);
MATCH (wt:WorkoutType {name: "Cardio"}), (fp:FitnessProgram {name: "P90 Deluxe Upgrade Package"}) WITH wt, fp CREATE (fp)-[:INVOLVES]->(wt);
MATCH (wt:WorkoutType {name: "Cardio"}), (fp:FitnessProgram {name: "P90 Speed Series DVDs"}) WITH wt, fp CREATE (fp)-[:INVOLVES]->(wt);
MATCH (wt:WorkoutType {name: "Cardio"}), (fp:FitnessProgram {name: "PiYo Strength® DVD"}) WITH wt, fp CREATE (fp)-[:INVOLVES]->(wt);
MATCH (wt:WorkoutType {name: "Cardio"}), (fp:FitnessProgram {name: "PiYo Hardcore on the Floor DVD"}) WITH wt, fp CREATE (fp)-[:INVOLVES]->(wt);
MATCH (wt:WorkoutType {name: "Cardio"}), (fp:FitnessProgram {name: "TurboFire"}) WITH wt, fp CREATE (fp)-[:INVOLVES]->(wt);
MATCH (wt:WorkoutType {name: "Cardio"}), (fp:FitnessProgram {name: "TurboFire Advanced Classes"}) WITH wt, fp CREATE (fp)-[:INVOLVES]->(wt);
MATCH (wt:WorkoutType {name: "Cardio"}), (fp:FitnessProgram {name: "INSANITY: THE ASYLUM"}) WITH wt, fp CREATE (fp)-[:INVOLVES]->(wt);
MATCH (wt:WorkoutType {name: "Cardio"}), (fp:FitnessProgram {name: "INSANITY: THE ASYLUM Volume 2"}) WITH wt, fp CREATE (fp)-[:INVOLVES]->(wt);
MATCH (wt:WorkoutType {name: "Cardio"}), (fp:FitnessProgram {name: "Hip Hop Abs"}) WITH wt, fp CREATE (fp)-[:INVOLVES]->(wt);
MATCH (wt:WorkoutType {name: "Cardio"}), (fp:FitnessProgram {name: "Turbo Jam"}) WITH wt, fp CREATE (fp)-[:INVOLVES]->(wt);
MATCH (wt:WorkoutType {name: "Cardio"}), (fp:FitnessProgram {name: "Brazil Butt Lift"}) WITH wt, fp CREATE (fp)-[:INVOLVES]->(wt);
MATCH (wt:WorkoutType {name: "Cardio"}), (fp:FitnessProgram {name: "P90X Plus"}) WITH wt, fp CREATE (fp)-[:INVOLVES]->(wt);
MATCH (wt:WorkoutType {name: "Cardio"}), (fp:FitnessProgram {name: "Turbo Jam Fat Burning Elite"}) WITH wt, fp CREATE (fp)-[:INVOLVES]->(wt);
MATCH (wt:WorkoutType {name: "Cardio"}), (fp:FitnessProgram {name: "INSANITY Deluxe"}) WITH wt, fp CREATE (fp)-[:INVOLVES]->(wt);
MATCH (wt:WorkoutType {name: "Cardio"}), (fp:FitnessProgram {name: "INSANITY Fast and Furious"}) WITH wt, fp CREATE (fp)-[:INVOLVES]->(wt);
MATCH (wt:WorkoutType {name: "Cardio"}), (fp:FitnessProgram {name: "INSANITY Sanity Check"}) WITH wt, fp CREATE (fp)-[:INVOLVES]->(wt);
MATCH (wt:WorkoutType {name: "Cardio"}), (fp:FitnessProgram {name: "INSANITY Fast and Furious Abs"}) WITH wt, fp CREATE (fp)-[:INVOLVES]->(wt);
MATCH (wt:WorkoutType {name: "Cardio"}), (fp:FitnessProgram {name: "Brazil Butt Lift Deluxe"}) WITH wt, fp CREATE (fp)-[:INVOLVES]->(wt);
MATCH (wt:WorkoutType {name: "Cardio"}), (fp:FitnessProgram {name: "FOCUS T25 GAMMA Deluxe"}) WITH wt, fp CREATE (fp)-[:INVOLVES]->(wt);
MATCH (wt:WorkoutType {name: "Cardio"}), (fp:FitnessProgram {name: "FOCUS T25 Core Speed"}) WITH wt, fp CREATE (fp)-[:INVOLVES]->(wt);
// Connect Muscle Groups to Fitness Programs
MATCH (mg:MuscleGroup {name: "Abs"}), (fp:FitnessProgram {name: "The Master's Hammer and Chisel"}) WITH mg, fp CREATE (fp)-[:TARGETS]->(mg);
MATCH (mg:MuscleGroup {name: "Abs"}), (fp:FitnessProgram {name: "PiYo Hardcore on the Floor DVD"}) WITH mg, fp CREATE (fp)-[:TARGETS]->(mg);
MATCH (mg:MuscleGroup {name: "Abs"}), (fp:FitnessProgram {name: "The Master's Hammer and Chisel Deluxe Upgrade"}) WITH mg, fp CREATE (fp)-[:TARGETS]->(mg);
MATCH (mg:MuscleGroup {name: "Abs"}), (fp:FitnessProgram {name: "The Master's Hammer and Chisel Deluxe Workouts—DVD Workout"}) WITH mg, fp CREATE (fp)-[:TARGETS]->(mg);
MATCH (mg:MuscleGroup {name: "Abs"}), (fp:FitnessProgram {name: "21 Day Fix EXTREME"}) WITH mg, fp CREATE (fp)-[:TARGETS]->(mg);
MATCH (mg:MuscleGroup {name: "Abs"}), (fp:FitnessProgram {name: "INSANITY MAX:30"}) WITH mg, fp CREATE (fp)-[:TARGETS]->(mg);
MATCH (mg:MuscleGroup {name: "Abs"}), (fp:FitnessProgram {name: "21 Day Fix"}) WITH mg, fp CREATE (fp)-[:TARGETS]->(mg);
MATCH (mg:MuscleGroup {name: "Abs"}), (fp:FitnessProgram {name: "FOCUS T25"}) WITH mg, fp CREATE (fp)-[:TARGETS]->(mg);
MATCH (mg:MuscleGroup {name: "Abs"}), (fp:FitnessProgram {name: "P90X3"}) WITH mg, fp CREATE (fp)-[:TARGETS]->(mg);
MATCH (mg:MuscleGroup {name: "Abs"}), (fp:FitnessProgram {name: "PiYo"}) WITH mg, fp CREATE (fp)-[:TARGETS]->(mg);
MATCH (mg:MuscleGroup {name: "Abs"}), (fp:FitnessProgram {name: "INSANITY MAX:30 Ab Maximizer Kit"}) WITH mg, fp CREATE (fp)-[:TARGETS]->(mg);
MATCH (mg:MuscleGroup {name: "Abs"}), (fp:FitnessProgram {name: "PiYo Strength® DVD"}) WITH mg, fp CREATE (fp)-[:TARGETS]->(mg);
MATCH (mg:MuscleGroup {name: "Abs"}), (fp:FitnessProgram {name: "P90"}) WITH mg, fp CREATE (fp)-[:TARGETS]->(mg);
MATCH (mg:MuscleGroup {name: "Abs"}), (fp:FitnessProgram {name: "TurboFire"}) WITH mg, fp CREATE (fp)-[:TARGETS]->(mg);
MATCH (mg:MuscleGroup {name: "Abs"}), (fp:FitnessProgram {name: "TurboFire Advanced Classes"}) WITH mg, fp CREATE (fp)-[:TARGETS]->(mg);
MATCH (mg:MuscleGroup {name: "Abs"}), (fp:FitnessProgram {name: "P90X"}) WITH mg, fp CREATE (fp)-[:TARGETS]->(mg);
MATCH (mg:MuscleGroup {name: "Abs"}), (fp:FitnessProgram {name: "Hip Hop Abs"}) WITH mg, fp CREATE (fp)-[:TARGETS]->(mg);
MATCH (mg:MuscleGroup {name: "Abs"}), (fp:FitnessProgram {name: "Turbo Jam"}) WITH mg, fp CREATE (fp)-[:TARGETS]->(mg);
MATCH (mg:MuscleGroup {name: "Abs"}), (fp:FitnessProgram {name: "Yoga Booty Ballet Ab & Butt Makeover"}) WITH mg, fp CREATE (fp)-[:TARGETS]->(mg);
MATCH (mg:MuscleGroup {name: "Abs"}), (fp:FitnessProgram {name: "INSANITY: THE ASYLUM"}) WITH mg, fp CREATE (fp)-[:TARGETS]->(mg);
MATCH (mg:MuscleGroup {name: "Abs"}), (fp:FitnessProgram {name: "INSANITY: THE ASYLUM Volume 2"}) WITH mg, fp CREATE (fp)-[:TARGETS]->(mg);
MATCH (mg:MuscleGroup {name: "Abs"}), (fp:FitnessProgram {name: "INSANITY Deluxe"}) WITH mg, fp CREATE (fp)-[:TARGETS]->(mg);
MATCH (mg:MuscleGroup {name: "Abs"}), (fp:FitnessProgram {name: "INSANITY Fast and Furious Abs"}) WITH mg, fp CREATE (fp)-[:TARGETS]->(mg);
// Connect Categories to Fitness Programs
MATCH (c:Category {name: "Best Sellers"}), (fp:FitnessProgram {name: "The Master's Hammer and Chisel"}) WITH c, fp CREATE (c)-[:CONTAINS]->(fp);
MATCH (c:Category {name: "Best Sellers"}), (fp:FitnessProgram {name: "CIZE"}) WITH c, fp CREATE (c)-[:CONTAINS]->(fp);
MATCH (c:Category {name: "Best Sellers"}), (fp:FitnessProgram {name: "21 Day Fix"}) WITH c, fp CREATE (c)-[:CONTAINS]->(fp);
MATCH (c:Category {name: "Best Sellers"}), (fp:FitnessProgram {name: "INSANITY MAX:30™"}) WITH c, fp CREATE (c)-[:CONTAINS]->(fp);
MATCH (c:Category {name: "Best Sellers"}), (fp:FitnessProgram {name: "21 Day Fix EXTREME"}) WITH c, fp CREATE (c)-[:CONTAINS]->(fp);
MATCH (c:Category {name: "Best Sellers"}), (fp:FitnessProgram {name: "P90"}) WITH c, fp CREATE (c)-[:CONTAINS]->(fp);
MATCH (c:Category {name: "Best Sellers"}), (fp:FitnessProgram {name: "PiYo"}) WITH c, fp CREATE (c)-[:CONTAINS]->(fp);
MATCH (c:Category {name: "Best Sellers"}), (fp:FitnessProgram {name: "FOCUS T25"}) WITH c, fp CREATE (c)-[:CONTAINS]->(fp);
MATCH (c:Category {name: "Best Sellers"}), (fp:FitnessProgram {name: "P90X3"}) WITH c, fp CREATE (c)-[:CONTAINS]->(fp);
MATCH (c:Category {name: "Best Sellers"}), (fp:FitnessProgram {name: "INSANITY"}) WITH c, fp CREATE (c)-[:CONTAINS]->(fp);
MATCH (c:Category {name: "Best Sellers"}), (fp:FitnessProgram {name: "Brazil Butt Lift"}) WITH c, fp CREATE (c)-[:CONTAINS]->(fp);
MATCH (c:Category {name: "Best Sellers"}), (fp:FitnessProgram {name: "Tony Horton's 10-Minute Trainer"}) WITH c, fp CREATE (c)-[:CONTAINS]->(fp);
MATCH (c:Category {name: "Best Sellers"}), (fp:FitnessProgram {name: "P90X2"}) WITH c, fp CREATE (c)-[:CONTAINS]->(fp);
MATCH (c:Category {name: "Best Sellers"}), (fp:FitnessProgram {name: "TurboFire"}) WITH c, fp CREATE (c)-[:CONTAINS]->(fp);
MATCH (c:Category {name: "Best Sellers"}), (fp:FitnessProgram {name: "INSANITY: THE ASYLUM"}) WITH c, fp CREATE (c)-[:CONTAINS]->(fp);
// Connect Physical Limitations to Fitness Programs
MATCH (pl:PhysicalLimitation {name: "Asthma"}), (fp:FitnessProgram {name: "CIZE"}) WITH pl, fp CREATE (fp)-[:LIMITED_BY]->(pl);
MATCH (pl:PhysicalLimitation {name: "Asthma"}), (fp:FitnessProgram {name: "21 Day Fix"}) WITH pl, fp CREATE (fp)-[:LIMITED_BY]->(pl);
MATCH (pl:PhysicalLimitation {name: "Asthma"}), (fp:FitnessProgram {name: "INSANITY MAX:30"}) WITH pl, fp CREATE (fp)-[:LIMITED_BY]->(pl);
MATCH (pl:PhysicalLimitation {name: "Asthma"}), (fp:FitnessProgram {name: "FOCUS T25"}) WITH pl, fp CREATE (fp)-[:LIMITED_BY]->(pl);
MATCH (pl:PhysicalLimitation {name: "Asthma"}), (fp:FitnessProgram {name: "21 Day Fix EXTREME"}) WITH pl, fp CREATE (fp)-[:LIMITED_BY]->(pl);
MATCH (pl:PhysicalLimitation {name: "Asthma"}), (fp:FitnessProgram {name: "PiYo"}) WITH pl, fp CREATE (fp)-[:LIMITED_BY]->(pl);
MATCH (pl:PhysicalLimitation {name: "Asthma"}), (fp:FitnessProgram {name: "CIZE Weight Loss Series Upgrade"}) WITH pl, fp CREATE (fp)-[:LIMITED_BY]->(pl);
MATCH (pl:PhysicalLimitation {name: "Asthma"}), (fp:FitnessProgram {name: "CIZE Weight Loss Series DVD only"}) WITH pl, fp CREATE (fp)-[:LIMITED_BY]->(pl);
MATCH (pl:PhysicalLimitation {name: "Asthma"}), (fp:FitnessProgram {name: "P90"}) WITH pl, fp CREATE (fp)-[:LIMITED_BY]->(pl);
MATCH (pl:PhysicalLimitation {name: "Asthma"}), (fp:FitnessProgram {name: "INSANITY MAX:30 Ab Maximizer Kit"}) WITH pl, fp CREATE (fp)-[:LIMITED_BY]->(pl);
MATCH (pl:PhysicalLimitation {name: "Asthma"}), (fp:FitnessProgram {name: "Rockin' Body"}) WITH pl, fp CREATE (fp)-[:LIMITED_BY]->(pl);
MATCH (pl:PhysicalLimitation {name: "Asthma"}), (fp:FitnessProgram {name: "INSANITY"}) WITH pl, fp CREATE (fp)-[:LIMITED_BY]->(pl);
MATCH (pl:PhysicalLimitation {name: "Asthma"}), (fp:FitnessProgram {name: "P90 Deluxe Upgrade Package"}) WITH pl, fp CREATE (fp)-[:LIMITED_BY]->(pl);
MATCH (pl:PhysicalLimitation {name: "Asthma"}), (fp:FitnessProgram {name: "P90 Speed Series DVDs"}) WITH pl, fp CREATE (fp)-[:LIMITED_BY]->(pl);
MATCH (pl:PhysicalLimitation {name: "Asthma"}), (fp:FitnessProgram {name: "PiYo Strength® DVD"}) WITH pl, fp CREATE (fp)-[:LIMITED_BY]->(pl);
MATCH (pl:PhysicalLimitation {name: "Asthma"}), (fp:FitnessProgram {name: "PiYo Hardcore on the Floor DVD"}) WITH pl, fp CREATE (fp)-[:LIMITED_BY]->(pl);
MATCH (pl:PhysicalLimitation {name: "Asthma"}), (fp:FitnessProgram {name: "TurboFire"}) WITH pl, fp CREATE (fp)-[:LIMITED_BY]->(pl);
MATCH (pl:PhysicalLimitation {name: "Asthma"}), (fp:FitnessProgram {name: "TurboFire Advanced Classes"}) WITH pl, fp CREATE (fp)-[:LIMITED_BY]->(pl);
MATCH (pl:PhysicalLimitation {name: "Asthma"}), (fp:FitnessProgram {name: "INSANITY: THE ASYLUM"}) WITH pl, fp CREATE (fp)-[:LIMITED_BY]->(pl);
MATCH (pl:PhysicalLimitation {name: "Asthma"}), (fp:FitnessProgram {name: "INSANITY: THE ASYLUM Volume 2"}) WITH pl, fp CREATE (fp)-[:LIMITED_BY]->(pl);
MATCH (pl:PhysicalLimitation {name: "Asthma"}), (fp:FitnessProgram {name: "Hip Hop Abs"}) WITH pl, fp CREATE (fp)-[:LIMITED_BY]->(pl);
MATCH (pl:PhysicalLimitation {name: "Asthma"}), (fp:FitnessProgram {name: "Turbo Jam"}) WITH pl, fp CREATE (fp)-[:LIMITED_BY]->(pl);
MATCH (pl:PhysicalLimitation {name: "Asthma"}), (fp:FitnessProgram {name: "Brazil Butt Lift"}) WITH pl, fp CREATE (fp)-[:LIMITED_BY]->(pl);
MATCH (pl:PhysicalLimitation {name: "Asthma"}), (fp:FitnessProgram {name: "P90X Plus"}) WITH pl, fp CREATE (fp)-[:LIMITED_BY]->(pl);
MATCH (pl:PhysicalLimitation {name: "Asthma"}), (fp:FitnessProgram {name: "Turbo Jam Fat Burning Elite"}) WITH pl, fp CREATE (fp)-[:LIMITED_BY]->(pl);
MATCH (pl:PhysicalLimitation {name: "Asthma"}), (fp:FitnessProgram {name: "INSANITY Deluxe"}) WITH pl, fp CREATE (fp)-[:LIMITED_BY]->(pl);
MATCH (pl:PhysicalLimitation {name: "Asthma"}), (fp:FitnessProgram {name: "INSANITY Fast and Furious"}) WITH pl, fp CREATE (fp)-[:LIMITED_BY]->(pl);
MATCH (pl:PhysicalLimitation {name: "Asthma"}), (fp:FitnessProgram {name: "INSANITY Sanity Check"}) WITH pl, fp CREATE (fp)-[:LIMITED_BY]->(pl);
MATCH (pl:PhysicalLimitation {name: "Asthma"}), (fp:FitnessProgram {name: "INSANITY Fast and Furious Abs"}) WITH pl, fp CREATE (fp)-[:LIMITED_BY]->(pl);
MATCH (pl:PhysicalLimitation {name: "Asthma"}), (fp:FitnessProgram {name: "Brazil Butt Lift Deluxe"}) WITH pl, fp CREATE (fp)-[:LIMITED_BY]->(pl);
MATCH (pl:PhysicalLimitation {name: "Asthma"}), (fp:FitnessProgram {name: "FOCUS T25 GAMMA Deluxe"}) WITH pl, fp CREATE (fp)-[:LIMITED_BY]->(pl);
MATCH (pl:PhysicalLimitation {name: "Asthma"}), (fp:FitnessProgram {name: "FOCUS T25 Core Speed"}) WITH pl, fp CREATE (fp)-[:LIMITED_BY]->(pl);
// Create Nutritional Supplements
CREATE (ns:NutritionalSupplement {name: "Shakeology"}) SET ns.displayName = "Shakeology®";
CREATE (ns:NutritionalSupplement {name: "Beachbody Performance Line"}) SET ns.displayName = "Beachbody Performance™ Line";
CREATE (ns:NutritionalSupplement {name: "FIXATE Cookbook"}) SET ns.displayName = "FIXATE™ Cookbook";
CREATE (ns:NutritionalSupplement {name: "E&E Energy and Endurance"}) SET ns.displayName = "E&E Energy and Endurance®";
CREATE (ns:NutritionalSupplement {name: "3-Day Refresh"}) SET ns.displayName = "3-Day Refresh™";
CREATE (ns:NutritionalSupplement {name: "FIXATE Cookbook and Beachbody Portion-Control Container Kit"}) SET ns.displayName = "FIXATE™ Cookbook and Beachbody® Portion-Control Container Kit";
CREATE (ns:NutritionalSupplement {name: "Beachbody Ultimate Reset"}) SET ns.displayName = "Beachbody Ultimate Reset®";
CREATE (ns:NutritionalSupplement {name: "Beachbody Hardcore Base Shake 30-Day Supply"}) SET ns.displayName = "Beachbody® Hardcore Base Shake 30-Day Supply";
CREATE (ns:NutritionalSupplement {name: "Beachbody Fuel Shot 30-Day Supply"}) SET ns.displayName = "Beachbody® Fuel Shot 30-Day Supply";
CREATE (ns:NutritionalSupplement {name: "Beachbody M.A.X. Creatine 30-Day Supply"}) SET ns.displayName = "Beachbody® M.A.X. Creatine 30-Day Supply";
CREATE (ns:NutritionalSupplement {name: "P90X Results and Recovery Formula"}) SET ns.displayName = "P90X® Results and Recovery Formula®";
CREATE (ns:NutritionalSupplement {name: "Core Omega-3"}) SET ns.displayName = "Core Omega-3™";
CREATE (ns:NutritionalSupplement {name: "ActiVit Multivitamins"}) SET ns.displayName = "ActiVit® Multivitamins";
CREATE (ns:NutritionalSupplement {name: "P90X Peak Performance Protein Bars"}) SET ns.displayName = "P90X® Peak Performance Protein Bars";
CREATE (ns:NutritionalSupplement {name: "Beachbody Performance Advanced Performance Stack"}) SET ns.displayName = "Beachbody Performance™ Advanced Performance Stack";
CREATE (ns:NutritionalSupplement {name: "Beachbody Performance Energize Pre-Workout Formula"}) SET ns.displayName = "Beachbody Performance™ Energize Pre-Workout Formula";
CREATE (ns:NutritionalSupplement {name: "Beachbody Performance Hydrate During Workout Formula"}) SET ns.displayName = "Beachbody Performance™ Hydrate During Workout Formula";
CREATE (ns:NutritionalSupplement {name: "Beachbody Performance Recover Post-Workout Formula"}) SET ns.displayName = "Beachbody Performance™ Recover Post-Workout Formula";
CREATE (ns:NutritionalSupplement {name: "Beachbody Performance Recharge Nighttime Recovery"}) SET ns.displayName = "Beachbody Performance™ Recharge Nighttime Recovery";
CREATE (ns:NutritionalSupplement {name: "Beachbody Performance Creatine"}) SET ns.displayName = "Beachbody Performance™ Creatine";
CREATE (ns:NutritionalSupplement {name: "Beachbody Performance Energize – 10 Single-Serving Packets"}) SET ns.displayName = "Beachbody Performance™ Energize – 10 Single-Serving Packets";
CREATE (ns:NutritionalSupplement {name: "Beachbody Performance Ultimate Performance Stack"}) SET ns.displayName = "Beachbody Performance™ Ultimate Performance Stack";
CREATE (ns:NutritionalSupplement {name: "Beachbody Performance Hydrate – 10 Single-Serving Packets"}) SET ns.displayName = "Beachbody Performance™ Hydrate – 10 Single-Serving Packets";
CREATE (ns:NutritionalSupplement {name: "Beachbody Performance Sampler Kit"}) SET ns.displayName = "Beachbody Performance™ Sampler Kit";
CREATE (ns:NutritionalSupplement {name: "Meal Replacement Shake; 30-day supply"}) SET ns.displayName = "Meal Replacement Shake; 30-day supply";
// Connect Workout Goals to Nutritional Supplements
MATCH (wg:WorkoutGoal {name: "Lose Weight"}), (ns:NutritionalSupplement {name: "Shakeology"}) WITH wg, ns CREATE (ns)-[:ASSISTS_WITH]->(wg);
// Connect Eating Goals to Nutritional Supplements
MATCH (eg:EatingGoal {name: "Get Healthy"}), (ns:NutritionalSupplement {name: "P90X Peak Performance Protein Bars"}) WITH eg, ns CREATE (ns)-[:ASSISTS_WITH]->(eg);
MATCH (eg:EatingGoal {name: "Get Healthy"}), (ns:NutritionalSupplement {name: "P90X Results and Recovery Formula"}) WITH eg, ns CREATE (ns)-[:ASSISTS_WITH]->(eg);
MATCH (eg:EatingGoal {name: "Get Healthy"}), (ns:NutritionalSupplement {name: "Shakeology"}) WITH eg, ns CREATE (ns)-[:ASSISTS_WITH]->(eg);
MATCH (eg:EatingGoal {name: "Get Healthy"}), (ns:NutritionalSupplement {name: "ActiVit Multivitamins"}) WITH eg, ns CREATE (ns)-[:ASSISTS_WITH]->(eg);
MATCH (eg:EatingGoal {name: "Performance"}), (ns:NutritionalSupplement {name: "Beachbody Performance Advanced Performance Stack"}) WITH eg, ns CREATE (ns)-[:ASSISTS_WITH]->(eg);
MATCH (eg:EatingGoal {name: "Performance"}), (ns:NutritionalSupplement {name: "Beachbody Performance Performance Stack"}) WITH eg, ns CREATE (ns)-[:ASSISTS_WITH]->(eg);
MATCH (eg:EatingGoal {name: "Performance"}), (ns:NutritionalSupplement {name: "Beachbody Performance Energize Pre-Workout Formula"}) WITH eg, ns CREATE (ns)-[:ASSISTS_WITH]->(eg);
MATCH (eg:EatingGoal {name: "Performance"}), (ns:NutritionalSupplement {name: "Beachbody Performance Hydrate During Workout Formula"}) WITH eg, ns CREATE (ns)-[:ASSISTS_WITH]->(eg);
MATCH (eg:EatingGoal {name: "Performance"}), (ns:NutritionalSupplement {name: "Beachbody Performance Recover Post-Workout Formula"}) WITH eg, ns CREATE (ns)-[:ASSISTS_WITH]->(eg);
MATCH (eg:EatingGoal {name: "Performance"}), (ns:NutritionalSupplement {name: "Beachbody Performance Recharge Nighttime Recovery"}) WITH eg, ns CREATE (ns)-[:ASSISTS_WITH]->(eg);
MATCH (eg:EatingGoal {name: "Performance"}), (ns:NutritionalSupplement {name: "Beachbody Performance Creatine"}) WITH eg, ns CREATE (ns)-[:ASSISTS_WITH]->(eg);
MATCH (eg:EatingGoal {name: "Performance"}), (ns:NutritionalSupplement {name: "Beachbody Performance Energize – 10 Single-Serving Packets"}) WITH eg, ns CREATE (ns)-[:ASSISTS_WITH]->(eg);
MATCH (eg:EatingGoal {name: "Performance"}), (ns:NutritionalSupplement {name: "Beachbody Performance Ultimate Performance Stack"}) WITH eg, ns CREATE (ns)-[:ASSISTS_WITH]->(eg);
MATCH (eg:EatingGoal {name: "Performance"}), (ns:NutritionalSupplement {name: "Beachbody Performance Hydrate – 10 Single-Serving Packets"}) WITH eg, ns CREATE (ns)-[:ASSISTS_WITH]->(eg);
MATCH (eg:EatingGoal {name: "Performance"}), (ns:NutritionalSupplement {name: "Beachbody Performance Sampler Kit"}) WITH eg, ns CREATE (ns)-[:ASSISTS_WITH]->(eg);
MATCH (eg:EatingGoal {name: "Performance"}), (ns:NutritionalSupplement {name: "P90X Peak Performance Protein Bars"}) WITH eg, ns CREATE (ns)-[:ASSISTS_WITH]->(eg);
MATCH (eg:EatingGoal {name: "Performance"}), (ns:NutritionalSupplement {name: "E&E Energy and Endurance"}) WITH eg, ns CREATE (ns)-[:ASSISTS_WITH]->(eg);
MATCH (eg:EatingGoal {name: "Performance"}), (ns:NutritionalSupplement {name: "P90X Results and Recovery Formula"}) WITH eg, ns CREATE (ns)-[:ASSISTS_WITH]->(eg);
MATCH (eg:EatingGoal {name: "Muscle Enhancement"}), (ns:NutritionalSupplement {name: "Beachbody Performance Line"}) WITH eg, ns CREATE (ns)-[:ASSISTS_WITH]->(eg);
MATCH (eg:EatingGoal {name: "Muscle Enhancement"}), (ns:NutritionalSupplement {name: "E&E Energy and Endurance"}) WITH eg, ns CREATE (ns)-[:ASSISTS_WITH]->(eg);
MATCH (eg:EatingGoal {name: "Muscle Enhancement"}), (ns:NutritionalSupplement {name: "Beachbody Hardcore Base Shake 30-Day Supply"}) WITH eg, ns CREATE (ns)-[:ASSISTS_WITH]->(eg);
MATCH (eg:EatingGoal {name: "Muscle Enhancement"}), (ns:NutritionalSupplement {name: "Beachbody Fuel Shot 30-Day Supply"}) WITH eg, ns CREATE (ns)-[:ASSISTS_WITH]->(eg);
MATCH (eg:EatingGoal {name: "Muscle Enhancement"}), (ns:NutritionalSupplement {name: "Beachbody M.A.X. Creatine 30-Day Supply"}) WITH eg, ns CREATE (ns)-[:ASSISTS_WITH]->(eg);
MATCH (eg:EatingGoal {name: "Wellness"}), (ns:NutritionalSupplement {name: "Shakeology"}) WITH eg, ns CREATE (ns)-[:ASSISTS_WITH]->(eg);
MATCH (eg:EatingGoal {name: "Wellness"}), (ns:NutritionalSupplement {name: "3-Day Refresh"}) WITH eg, ns CREATE (ns)-[:ASSISTS_WITH]->(eg);
MATCH (eg:EatingGoal {name: "Wellness"}), (ns:NutritionalSupplement {name: "Meal Replacement Shake; 30-day supply"}) WITH eg, ns CREATE (ns)-[:ASSISTS_WITH]->(eg);
MATCH (eg:EatingGoal {name: "Wellness"}), (ns:NutritionalSupplement {name: "Core Omega-3"}) WITH eg, ns CREATE (ns)-[:ASSISTS_WITH]->(eg);
MATCH (eg:EatingGoal {name: "Weight Loss"}), (ns:NutritionalSupplement {name: "Beachbody Performance Line"}) WITH eg, ns CREATE (ns)-[:ASSISTS_WITH]->(eg);
MATCH (eg:EatingGoal {name: "Weight Loss"}), (ns:NutritionalSupplement {name: "3-Day Refresh"}) WITH eg, ns CREATE (ns)-[:ASSISTS_WITH]->(eg);
MATCH (eg:EatingGoal {name: "Weight Loss"}), (ns:NutritionalSupplement {name: "Shakeology"}) WITH eg, ns CREATE (ns)-[:ASSISTS_WITH]->(eg);
MATCH (eg:EatingGoal {name: "Weight Loss"}), (ns:NutritionalSupplement {name: "Beachbody Ultimate Reset"}) WITH eg, ns CREATE (ns)-[:ASSISTS_WITH]->(eg);
MATCH (eg:EatingGoal {name: "Weight Loss"}), (ns:NutritionalSupplement {name: "ActiVit Multivitamins"}) WITH eg, ns CREATE (ns)-[:ASSISTS_WITH]->(eg);
// Connect Supplement Types to Nutritional Supplements
MATCH (st:SupplementType {name: "Beachbody Performance"}), (ns:NutritionalSupplement {name: "Beachbody Performance Advanced Performance Stack"}) WITH st, ns CREATE (ns)-[:IS_TYPE]->(st);
MATCH (st:SupplementType {name: "Beachbody Performance"}), (ns:NutritionalSupplement {name: "Beachbody Performance Performance Stack"}) WITH st, ns CREATE (ns)-[:IS_TYPE]->(st);
MATCH (st:SupplementType {name: "Beachbody Performance"}), (ns:NutritionalSupplement {name: "Beachbody Performance Energize Pre-Workout Formula"}) WITH st, ns CREATE (ns)-[:IS_TYPE]->(st);
MATCH (st:SupplementType {name: "Beachbody Performance"}), (ns:NutritionalSupplement {name: "Beachbody Performance Hydrate During Workout Formula"}) WITH st, ns CREATE (ns)-[:IS_TYPE]->(st);
MATCH (st:SupplementType {name: "Beachbody Performance"}), (ns:NutritionalSupplement {name: "Beachbody Performance Recover Post-Workout Formula"}) WITH st, ns CREATE (ns)-[:IS_TYPE]->(st);
MATCH (st:SupplementType {name: "Beachbody Performance"}), (ns:NutritionalSupplement {name: "Beachbody Performance Recharge Nighttime Recovery"}) WITH st, ns CREATE (ns)-[:IS_TYPE]->(st);
MATCH (st:SupplementType {name: "Beachbody Performance"}), (ns:NutritionalSupplement {name: "Beachbody Performance Creatine"}) WITH st, ns CREATE (ns)-[:IS_TYPE]->(st);
MATCH (st:SupplementType {name: "Beachbody Performance"}), (ns:NutritionalSupplement {name: "Beachbody Performance Energize – 10 Single-Serving Packets"}) WITH st, ns CREATE (ns)-[:IS_TYPE]->(st);
MATCH (st:SupplementType {name: "Beachbody Performance"}), (ns:NutritionalSupplement {name: "Beachbody Performance Ultimate Performance Stack"}) WITH st, ns CREATE (ns)-[:IS_TYPE]->(st);
MATCH (st:SupplementType {name: "Beachbody Performance"}), (ns:NutritionalSupplement {name: "Beachbody Performance Hydrate – 10 Single-Serving Packets"}) WITH st, ns CREATE (ns)-[:IS_TYPE]->(st);
MATCH (st:SupplementType {name: "Beachbody Performance"}), (ns:NutritionalSupplement {name: "Beachbody Performance Sampler Kit"}) WITH st, ns CREATE (ns)-[:IS_TYPE]->(st);
MATCH (st:SupplementType {name: "P90X Peak Performance"}), (ns:NutritionalSupplement {name: "P90X Peak Performance Protein Bars"}) WITH st, ns CREATE (ns)-[:IS_TYPE]->(st);
MATCH (st:SupplementType {name: "P90X Peak Performance"}), (ns:NutritionalSupplement {name: "E&E Energy and Endurance"}) WITH st, ns CREATE (ns)-[:IS_TYPE]->(st);
MATCH (st:SupplementType {name: "P90X Peak Performance"}), (ns:NutritionalSupplement {name: "P90X Results and Recovery Formula"}) WITH st, ns CREATE (ns)-[:IS_TYPE]->(st);
MATCH (st:SupplementType {name: "Meal Replacement"}), (ns:NutritionalSupplement {name: "Shakeology"}) WITH st, ns CREATE (ns)-[:IS_TYPE]->(st);
MATCH (st:SupplementType {name: "Meal Replacement"}), (ns:NutritionalSupplement {name: "3-Day Refresh"}) WITH st, ns CREATE (ns)-[:IS_TYPE]->(st);
MATCH (st:SupplementType {name: "Meal Replacement"}), (ns:NutritionalSupplement {name: "Meal Replacement Shake; 30-day supply"}) WITH st, ns CREATE (ns)-[:IS_TYPE]->(st);
MATCH (st:SupplementType {name: "Meal Replacement"}), (ns:NutritionalSupplement {name: "Beachbody Ultimate Reset"}) WITH st, ns CREATE (ns)-[:IS_TYPE]->(st);
MATCH (st:SupplementType {name: "Meal Replacement"}), (ns:NutritionalSupplement {name: "P90X Peak Performance Protein Bars"}) WITH st, ns CREATE (ns)-[:IS_TYPE]->(st);
MATCH (st:SupplementType {name: "Wellness"}), (ns:NutritionalSupplement {name: "Shakeology"}) WITH st, ns CREATE (ns)-[:IS_TYPE]->(st);
MATCH (st:SupplementType {name: "Wellness"}), (ns:NutritionalSupplement {name: "3-Day Refresh"}) WITH st, ns CREATE (ns)-[:IS_TYPE]->(st);
MATCH (st:SupplementType {name: "Wellness"}), (ns:NutritionalSupplement {name: "Meal Replacement Shake; 30-day supply"}) WITH st, ns CREATE (ns)-[:IS_TYPE]->(st);
MATCH (st:SupplementType {name: "Wellness"}), (ns:NutritionalSupplement {name: "Core Omega-3"}) WITH st, ns CREATE (ns)-[:IS_TYPE]->(st);
MATCH (st:SupplementType {name: "Weight Loss"}), (ns:NutritionalSupplement {name: "Beachbody Performance Line"}) WITH st, ns CREATE (ns)-[:IS_TYPE]->(st);
MATCH (st:SupplementType {name: "Weight Loss"}), (ns:NutritionalSupplement {name: "3-Day Refresh"}) WITH st, ns CREATE (ns)-[:IS_TYPE]->(st);
MATCH (st:SupplementType {name: "Weight Loss"}), (ns:NutritionalSupplement {name: "Shakeology"}) WITH st, ns CREATE (ns)-[:IS_TYPE]->(st);
MATCH (st:SupplementType {name: "Weight Loss"}), (ns:NutritionalSupplement {name: "Beachbody Ultimate Reset"}) WITH st, ns CREATE (ns)-[:IS_TYPE]->(st);
MATCH (st:SupplementType {name: "Weight Loss"}), (ns:NutritionalSupplement {name: "ActiVit Multivitamins"}) WITH st, ns CREATE (ns)-[:IS_TYPE]->(st);
// Connect Nutritional Supplements to Fintness Programs
MATCH (st:SupplementType {name: "Weight Loss"})<-[:IS_TYPE]-(ns), (wg:WorkoutGoal {name: "Weight Loss"})<-[:ACCOMPLISHES]-(fp) WITH st, ns, wg, fp MERGE (ns)-[:ASSISTS_WITH]->(wg) MERGE (fp)-[:BENEFITS_FROM]->(ns);
MATCH (st:SupplementType {name: "Beachbody Performance"})<-[:IS_TYPE]-(ns), (wg:WorkoutGoal {name: "Fat Burning"})<-[:ACCOMPLISHES]-(fp) WITH st, ns, wg, fp MERGE (ns)-[:ASSISTS_WITH]->(wg) MERGE (fp)-[:BENEFITS_FROM]->(ns);
MATCH (st:SupplementType {name: "P90X Peak Performance"})<-[:IS_TYPE]-(ns), (wg:WorkoutGoal {name: "Fat Burning"})<-[:ACCOMPLISHES]-(fp) WITH st, ns, wg, fp MERGE (ns)-[:ASSISTS_WITH]->(wg) MERGE (fp)-[:BENEFITS_FROM]->(ns);
MATCH (st:SupplementType {name: "Wellness"})<-[:IS_TYPE]-(ns), (wg:WorkoutGoal {name: "Get Fit"})<-[:ACCOMPLISHES]-(fp) WITH st, ns, wg, fp MERGE (ns)-[:ASSISTS_WITH]->(wg) MERGE (fp)-[:BENEFITS_FROM]->(ns);
MATCH (st:SupplementType {name: "P90X Peak Performance"})<-[:IS_TYPE]-(ns) WITH ns MATCH (fp:FitnessProgram) WHERE fp.name CONTAINS "P90X" WITH ns, fp MERGE (ns)-[:MADE_FOR]->(fp) MERGE (fp)-[:BENEFITS_FROM]->(ns);
// Connect Eating Goals to Fitness Programs
MATCH (eg:EatingGoal {name: "Get Healthy"})<-[:ASSISTS_WITH]-(ns), (wg:WorkoutGoal {name: "Get Fit"})<-[:ACCOMPLISHES]-(fp) WITH ns, wg, fp MERGE (ns)-[:ASSISTS_WITH]->(wg) MERGE (fp)-[:BENEFITS_FROM]->(ns);
// Connect User with Workout Goal to parallel Eating Goal
MATCH (eg:EatingGoal {name: "Weight Loss"}) WITH eg MATCH (wg:WorkoutGoal {name: "Weight Loss"})<-[r:DESIRES]-(u) WITH eg, wg, u, r.importance AS importance MERGE (u)-[r:DESIRES]->(eg) SET r.importance = toFloat(importance);
MATCH (eg:EatingGoal {name: "Wellness"}) WITH eg MATCH (wg:WorkoutGoal {name: "Get Fit"})<-[r:DESIRES]-(u) WITH eg, wg, u, r.importance AS importance MERGE (u)-[r:DESIRES]->(eg) SET r.importance = toFloat(importance);
MATCH (eg:EatingGoal {name: "Get Healthy"}) WITH eg MATCH (wg:WorkoutGoal {name: "Get Fit"})<-[r:DESIRES]-(u) WITH eg, wg, u, r.importance AS importance MERGE (u)-[r:DESIRES]->(eg) SET r.importance = toFloat(importance);
MATCH (eg:EatingGoal {name: "Performance"}) WITH eg MATCH (wg:WorkoutGoal {name: "Fat Burning"})<-[r:DESIRES]-(u) WITH eg, wg, u, r.importance AS importance MERGE (u)-[r:DESIRES]->(eg) SET r.importance = toFloat(importance);
MATCH (eg:EatingGoal {name: "Muscle Enhancement"}) WITH eg MATCH (wg:WorkoutGoal {name: "Fat Burning"})<-[r:DESIRES]-(u) WITH eg, wg, u, r.importance AS importance MERGE (u)-[r:DESIRES]->(eg) SET r.importance = toFloat(importance);加权边
最初,我们将首先探讨用户画像对各种锻炼目标、饮食目标、肌肉群和身体部位所赋予的“重要性”,这将用作评分算法的一部分。
// Order User's Values by Importance
MATCH (u:User {username: "ben"})-[r:VALUES]->(x) RETURN x.name, r.importance ORDER BY r.importance DESC;// Order User's Desires by Importance
MATCH (u:User {username: "ben"})-[r:DESIRES]->(x) RETURN x.name, r.importance ORDER BY r.importance DESC;个性化
用户的偏好对于充分了解他们以做出明智的推荐至关重要。在这里,我们从用户“ben”开始,遍历一层,到达我们通过与该用户的互动收集到的所有直接信息。
// Show User's Preferences
MATCH (u:User {username: "ben"}) WITH u MATCH (u)-[:HAS]->(pl:PhysicalLimitation), (u)-[:IS_AT]->(wl:WorkoutLevel), (u)-[:PREFERS]->(wt:WorkoutType), (u)-[:VALUES]->(ba:BodyArea), (u)-[:DESIRES]->(mg:MuscleGroup) RETURN u, pl, wl, wt, ba, mg;然后,我们查看所有用户,以及他们之间由“x”表示的分类节点。从这些“x”节点中,我们将找到所有与这些x相连的健身计划,这将构成我们的潜在推荐集合。
// Show All Users, Preferences/Classifcations and Fitness Programs
MATCH (u:User)-[]-(x)-[]-(u2:User)
OPTIONAL MATCH (x)-[]-(fp:FitnessProgram)
RETURN u, x, u2, fp;类似地,我们也可以从饮食目标开始,看看哪些营养补充剂和用户具有这些共同点。
// Explore Nutritional Supplements, Eating Goals and Users
MATCH (eg:EatingGoal) WITH eg OPTIONAL MATCH (eg)-[]-(x) RETURN eg, x;产品交叉销售
在这里,我们查看哪些饮食目标和锻炼目标可以视为并行关系,并由此可以检查用户没有直接连接时的模式。
// Explore Parallel Eating and Workout Goals - Performance/Fat Burning
MATCH (eg:EatingGoal {name: "Performance"})-[]-(x)-[]-(wg:WorkoutGoal {name: "Fat Burning"}) RETURN eg, x, wg;// Explore Parallel Eating and Workout Goals - Weight Loss
MATCH (eg:EatingGoal {name: "Weight Loss"})-[]-(x)-[]-(wg:WorkoutGoal {name: "Weight Loss"}) RETURN eg, x, wg;// Explore Parallel Eating and Workout Goals - Weight Loss/Get Healthy/Wellness
MATCH (eg:EatingGoal)-[]-(x)-[]-(wg:WorkoutGoal {name: "Weight Loss"}) WHERE eg.name = "Get Healthy" OR eg.name = "Wellness" RETURN eg, x, wg;推荐:为用户推荐健身计划
我们从简单开始,为用户推荐他们最喜欢的五个健身计划。
-
用户是我们的起始节点,从中我们可以选择性地引入任何身体限制,作为评分中的排除项。
-
然后,我们找到所有带有重要性权重的偏好。
-
接下来,我们需要获取所有与用户偏好相连的健身计划,并且不排除用户具有的任何身体限制。
-
然后,我们构建带有权重的特质,并对用户与可能被推荐的健身计划之间连接的重要性进行评分。
-
然后,我们按照该分数进行排序,并将返回结果集限制为5个。
// Recommend User a Fitness Program
MATCH (u:User) WHERE u.username = "ben" OPTIONAL MATCH (u)-[:HAS]->(pl)
WITH u, pl MATCH (u)-[r:IS_AT|PREFERS|DESIRES|VALUES]->(x)
WITH u, pl, x, coalesce(r.importance, 0.5) AS importance
MATCH (x)<-[]-(x2:FitnessProgram) WHERE NOT (x2)-[:LIMITED_BY]->(pl)
WITH u, x2, collect({name: x.name, weight: importance}) AS traits
WITH u, x2, reduce(s = 0, t IN traits | s + t.weight) AS score
WITH u, x2, score OPTIONAL MATCH (x2)-[]->(x)<-[]-(u)
RETURN x2, collect(x) AS x, u, score ORDER BY score DESC LIMIT 5;推荐:为用户推荐营养补充剂
这里的过程与健身计划相同,只是推荐的对象是营养补充剂。之所以可行,是因为这些类型之间的关系模式是相同的。
// Recommend User a Nutritional Supplement
MATCH (u:User) WHERE u.username = "ben" OPTIONAL MATCH (u)-[:HAS]->(pl)
WITH u, pl MATCH (u)-[r:IS_AT|PREFERS|DESIRES|VALUES]->(x)
WITH u, pl, x, coalesce(r.importance, 0.5) AS importance
MATCH (x)<-[]-(x2:NutritionalSupplement) WHERE NOT (x2)-[:LIMITED_BY]->(pl)
WITH u, x2, collect({name: x.name, weight: importance}) AS traits
WITH u, x2, reduce(s = 0, t IN traits | s + t.weight) AS score
WITH u, x2, score OPTIONAL MATCH (x2)-[]->(x)<-[]-(u)
RETURN x2, collect(x) AS x, u, score ORDER BY score DESC LIMIT 5;推荐:为用户推荐健身计划与营养补充剂的组合
这与第一条推荐类似,但只是允许将健身计划和营养补充剂都作为可能的推荐。
// Recommend User a blend of Fitness Programs and Nutrional Supplements
MATCH (u:User) WHERE u.username = "ben" OPTIONAL MATCH (u)-[:HAS]->(pl)
WITH u, pl MATCH (u)-[r:IS_AT|PREFERS|DESIRES|VALUES]->(x)
WITH u, pl, x, coalesce(r.importance, 0.5) AS importance
MATCH (x)<-[]-(x2) WHERE (x2:FitnessProgram OR x2:NutritionalSupplement) AND NOT (x2)-[:LIMITED_BY]->(pl)
WITH u, x2, collect({name: x.name, weight: importance}) AS traits
WITH u, x2, reduce(s = 0, t IN traits | s + t.weight) AS score
WITH u, x2, score OPTIONAL MATCH (x2)-[]->(x)<-[]-(u)
RETURN x2, collect(x) AS x, u, score ORDER BY score DESC LIMIT 5;推荐:推荐两个用户一起进行健身计划
在这里,我们进行了一些调整,以向一对应该一起体验健身计划的用户进行推荐。主要调整包括:
-
从起始用户的偏好出发,遍历出去以获取与他们相连的其他用户,这将构成可能被推荐的用户集合。
-
现在,我们对用户进行评分、排序,并将结果限制为最佳用户,然后继续为这两个用户找到最佳的健身计划。
-
从那时起,在我们找到可以同时推荐给这两个用户的健身计划之后,评分过程与之前相同。
// Recommend Two Users do a Fitness Program Together
MATCH (u:User) WHERE u.username = "ben" OPTIONAL MATCH (u)-[:HAS]->(pl)
WITH u, pl MATCH (u)-[r:IS_AT|PREFERS|DESIRES|VALUES]->(x)
WITH u, pl, x, coalesce(r.importance, 0.5) AS importance
MATCH (x)<-[]-(x2) WHERE (x2:User) AND NOT (x2)-[:LIMITED_BY]->(pl) AND u <> x2
WITH u, pl, x2, collect({name: x.name, weight: importance}) AS traits
WITH u, pl, x2, reduce(s = 0, t IN traits | s + t.weight) AS score
WITH u, pl, x2, score ORDER BY score DESC LIMIT 1
WITH u, pl, x2, score OPTIONAL MATCH (x2)-[]->(x)<-[]-(u), (x)<-[r]-(fp:FitnessProgram) WHERE NOT (fp)-[:LIMITED_BY]->(pl)
WITH u, x2, score, collect(x) AS common, fp, collect({name: x.name, weight: coalesce(r.importance, 0.5)}) AS traits
WITH u, x2, score, common, fp, reduce(s = 0, t IN traits | s + t.weight) AS score2
RETURN u, x2, score, common, fp, score2 ORDER BY score2 DESC LIMIT 1;此页面是否有帮助?