管理马匹血统簿
我在这篇 gist 中的目的是展示图数据库如何以非常自然的方式管理族谱。
我将讨论马匹的族谱,这通常由负责确保信息准确性和数据符合特定条件的机构在血统簿中管理。
本 gist 将展示
-
如何在血统簿中登记马匹,
-
如何检查一些一致性条件,
-
如何管理马匹与所有者、育种者和承租人之间的关系,
-
如何管理马匹的购买,以及
-
如何从血统簿中查询信息,例如马匹的血统、祖先或后代。
我们在此假设马匹在血统簿中只登记了一些基本数据:名称、出生年份、性别、毛色。我们还假设所有马匹都是纯种马,这样我们就不必担心品种兼容性。还可以登记许多其他数据,例如赛级和阿拉伯血统百分比(当血统簿用于杂交马时,如英阿杂交)、国籍、出生日期和地点等等:这些数据可以在更扩展的版本中进行管理。
一匹马如果能生育后代(即使尚未生育),则雌性可称为母马(mare),雄性可称为种马(stud):成为母马或种马是一种资格,马匹可以获得此资格,并对应于在血统簿中注册为种用马。
初始上传
已注册马匹的数据库初始上传可以按照以下说明进行
-
创建马匹实例
CREATE (h1:Horse {id: $registrationId, name: $horseName, birth_year: toInteger($birthYear), gender: $gender, mantle: $mantle })
其中 $gender 可以是 'F' 或 'M',$registrationId 是在血统簿中识别马匹的代码。
-
注册为种用马
对于雌性马匹
MATCH (h1:Horse {name: $horseName})
SET h1:Mare
或对于雄性马匹
MATCH (h1:Horse {name: $horseName})
SET h1:Stud
-
创建亲子关系
MATCH (m1:Mare {name: $MareName}) MATCH (h1:Horse {name: $horseName})
MATCH (s1:Stud {name: $StudName}) MATCH (h1:Horse {name: $horseName})
MERGE (m1)-[:DAM_OF]->(h1)
MERGE (s1)-[:SIRE_OF]->(h1)
这是一个用于上传一些起始数据的脚本
CREATE INDEX FOR (n:Horse) ON (n.name)
CREATE INDEX FOR (n:Mare) ON (n.name)
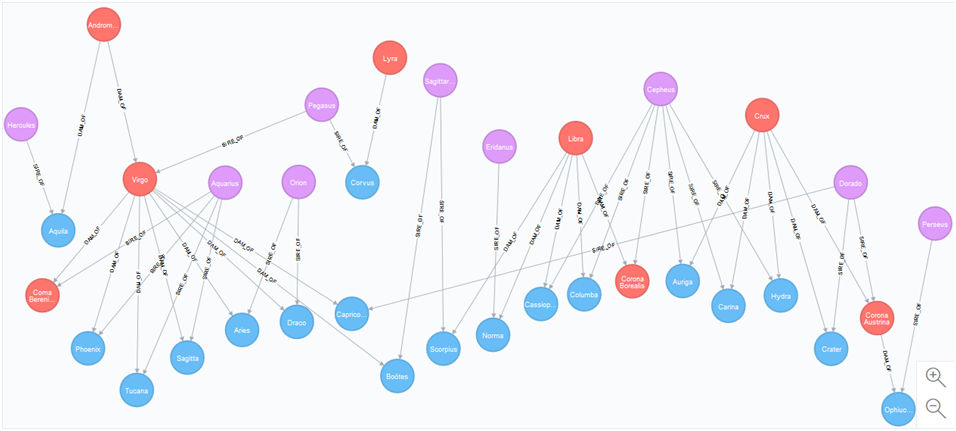
CREATE INDEX FOR (n:Stud) ON (n.name)初始数据给出以下图
一致性检查
为了长期保持数据正确,建议定期执行一些查询来验证是否存在异常情况。在从现有数据库进行大规模数据上传后,这些查询也至关重要:当所有这些查询都没有返回结果时,数据是一致的。
-
不存在循环
MATCH (parent)-[*]->(parent)
RETURN COUNT(parent)-
同一匹马不存在两个母亲或两个父亲
MATCH (dam1:Mare)-->(h:Horse), (dam2:Mare)-->(h)
WHERE exists((dam1)-->(h)<--(dam2))
RETURN DISTINCT h.name, dam1.name, dam2.nameMATCH (sire1:Stud)-->(h:Horse), (sire2:Stud)-->(h:Horse)
WHERE exists((sire1)-->(h)<--(sire2))
RETURN DISTINCT h.name, sire1.name, sire2.name-
不存在同一匹母马在同一年生育两个儿子的情况
MATCH (horse1:Horse)<--(dam:Mare)-->(horse2:Horse)
WHERE horse1.birth_year = horse2.birth_year
RETURN DISTINCT dam.name, horse1.name, horse2.name-
不存在母亲或父亲年龄过小而无法生育其后代的情况
MATCH (parent:Horse)-->(son:Horse)
WHERE parent.birth_year >= son.birth_year - 2
RETURN DISTINCT parent.name, parent.birth_year, son.name, son.birth_year-
不存在母亲年龄过大而无法生育其后代的情况
MATCH (dam:Mare)-->(son:Horse)
WHERE dam.birth_year < son.birth_year - 20
RETURN DISTINCT dam.name, dam.birth_year, son.name, son.birth_year至于种马,如果血统簿的规则允许人工授精,它们即使在年迈时也可以生育马驹;否则,也必须对种马进行类似的检查。
如何管理数据
现在我们来看看在一个允许我们管理血统簿数据的应用程序中应该包含哪些内容。
第一个功能是在血统簿中注册一匹新马,即马驹(foal)。
-
在血统簿的繁殖部分注册
在生育符合注册条件的马驹之前,未来的母亲(母系,dam)和未来的父亲(父系,sire)都必须在血统簿的相应部分注册为种用马,分别是母马(mare)和种马(stud)。
对于雌性马匹,注册为种用马的功能需要执行以下指令
MATCH (h:Horse {name: $name})
WHERE h.gender = 'F' AND NOT h:Mare
SET h:Mare
RETURN h.name as MareName, labels(h) as Labels
对于雄性马匹,需要以下指令
MATCH (h:Horse {name: $name})
WHERE h.gender = 'M' AND NOT h:Stud
SET h:Stud
RETURN h.name as StudName, labels(h) as Labels
在这两条指令中,条件确保我们
-
马匹性别正确
-
马匹尚未在注册簿中
只有同时满足这两个条件,才会执行注册。
-
在血统簿中注册马驹
当一匹马驹出生时,只有当其母系和父系都已注册时,才能在血统簿中注册。因此,执行此操作所需的指令如下
MATCH (sire:Stud {name: $sireName})
MATCH (dam:Mare {name: $dameName})
OPTIONAL MATCH (dam)<-[:SIRE_OF]-(damssire)
CREATE (foal:Horse {id: $registrationId, name: $foalName, birth_year: toInteger($birthYear), gender: $gender, mantle: $mantle})
CREATE (dam)-[:DAM_OF]->(foal)
CREATE (sire)-[:SIRE_OF]->(foal)
RETURN 'Foal registered: ' + foal.name + ' by ' + sire.name + ' out of ' + dam.name + ' (' + damssire.name + ')' as NewFoal
让我们仔细看看这条指令。首先,如果母系或父系未注册为种用马,则相应的 MATCH 将没有结果(标签过滤),马驹注册将失败。对于母系父系(即外祖父)的 OPTIONAL MATCH 是必需的,以避免在并非所有母系数据都立即可用时(例如,如果她是从外部导入的,或在族谱重建的情况下)匹配失败。
-
模型中的人类:育种者、所有者和承租人
相对于马匹,一个人可以扮演的主要角色包括
-
育种者(breeder):使其出生并至少在初期饲养它的人;
-
所有者(owner):对其拥有权利,但不一定与育种者相同;
-
承租人(tenant):从所有者那里获得临时权利的人。
一方面,公共契约足以证明一个人是否是马匹的所有者或承租人。另一方面,一个人作为产下马驹的母马的所有者或承租人,便成为了育种者。因此,一个人与马匹之间可能产生的角色源于人与马匹之间建立的关系。
在马驹出生时,母马的所有者或承租人会自动成为马驹的育种者或所有者:然后,之前看到的马驹注册指令必须按以下方式完成
MATCH (sire:Stud {name: $sireName})
MATCH (dam:Mare {name: $dameName})
OPTIONAL MATCH (dam)<-[:SIRE_OF]-(damssire)
CREATE (foal:Horse {name: $foalName, birth_year: toInteger($birtYear), gender: $gender, mantle: $mantle})
CREATE (dam)-[:DAM_OF]->(foal)
CREATE (sire)-[:SIRE_OF]->(foal)
WITH sire, dam, damssire, foal
MATCH (dam)<-[ownshp:OWNER_OF]-(owner)
OPTIONAL MATCH (dam)<-[tenshp:TENANT_OF]-(tenant)
WITH sire, dam, damssire, foal, coalesce(tenant, owner) as breeder, coalesce(tenshp, ownshp) as quote
CREATE (breeder)-[:BREEDER_OF {breed_perc: quote.property_perc}]->(foal)
CREATE (breeder)-[:OWNER_OF {property_perc: quote.property_perc}]->(foal)
RETURN DISTINCT 'Foal registered: ' + foal.name + ' by ' + sire.name + ' out of ' + dam.name + ' (' + damssire.name + ')' as NewFoal
让我们仔细看看。在创建新马驹及其与父母的关系后,脚本继续(第一个 WITH)获取母马的所有者和承租人(如果存在)(OPTIONAL 子句);然后(第二个 WITH)选择承租人或所有者作为马驹的育种者,无论如何都带有相应的产权百分比(变量 quote),最后创建产权和育种关系。返回的字符串具有典型的马匹命名形式,包含父系、母系和母系父系。显然,许多人可以是马匹的所有者或承租人:即使在这种情况下,脚本也能完美运行。
要检查人与马匹之间的所有关系是否一致,即每种关系类型的百分比总和对于所有马匹是否都为 100,必须将以下语句添加到要实现的一致性检查中
MATCH (p:Person)-[r:OWNER_OF]->(h:Horse) WITH h, sum(r.property_perc) as sum_property_perc WHERE sum_property_perc <> 100 RETURN h, sum_property_perc
其他关系类型(:BREEDER_OF, :TENANT_OF)也类似。
-
购买马匹
在购买马匹的情况下,可以通过以下指令获取新的产权配置(此处新所有者有三个,但可以是一到 n 个)
MATCH (h:Horse {name: $horseName})
OPTIONAL MATCH (h)<-[oldOwnshp:OWNER_OF]-()
DELETE oldOwnshp
WITH [{name:$newowner1, property_perc: toFloat($perc1)}
, {name:$newowner2, property_perc: toFloat($perc2)}
, {name:$newowner3, property_perc: toFloat($perc3)}
] AS purchaserList
UNWIND purchaserList AS purchaser
MERGE (p:Person {name: purchaser.name})
ON CREATE SET p.property_perc = purchaser.property_perc
ON MATCH SET p.property_perc = purchaser.property_perc
MERGE (p)-[newOwnshp:OWNER_OF]->(h)
SET newOwnshp.property_perc = p.property_perc
REMOVE p.property_perc
RETURN h.name, collect(p.name)
首先,删除旧的所有权关系(如果存在)。WITH 语句中是新所有者的列表,每个所有者都有其产权百分比。然后通过 UNWIND 将列表展开以获得新所有者的表格。对于数据库中每个已存在或新的所有者,临时为其分配产权百分比;当每个新所有者与马匹之间创建新的关系时,将百分比分配给关系,并从所有者中移除临时值。
租赁也可以写类似的指令,而繁殖权通常不能出售。
让我们看看 Cypher 的实际应用
我们现在将刚刚看到的指令应用于初始输入的数据。
让我们为三匹已注册的马匹添加一些相关人员:它们的育种者和所有者,以及其中一匹马的承租人
MATCH (h1:Horse {name: 'Scorpius'})
MATCH (h2:Horse {name: 'Tucana'})
MATCH (h3:Horse {name: 'Aries'})
CREATE (p1:Person {name: 'Julia Stokes'})
CREATE (p2:Person {name: 'Hugh Kelley'})
CREATE (p3:Person {name: 'Anne Nicholson'})
CREATE (p4:Person {name: 'Jeremy Dalton'})
CREATE (p5:Person {name: 'Beatrice Fowler'})
CREATE (p1)-[:BREEDER_OF {breed_perc: toFloat(100.0)}]-> (h1)
CREATE (p1)-[:OWNER_OF {property_perc: toFloat(100.0)}]-> (h1)
CREATE (p2)-[:BREEDER_OF {breed_perc: toFloat(100.0)}]-> (h2)
CREATE (p3)-[:OWNER_OF {property_perc: toFloat(60.0)}]-> (h2)
CREATE (p4)-[:OWNER_OF {property_perc: toFloat(40.0)}]-> (h2)
CREATE (p5)-[:BREEDER_OF {breed_perc: toFloat(100.0)}]-> (h3)
CREATE (p5)-[:OWNER_OF {property_perc: toFloat(100.0)}]-> (h3)
CREATE (p3)-[:TENANT_OF {rental_perc: toFloat(100.0)}]-> (h3)
RETURN h1,h2,h3,p1,p2,p3,p4,p5情况如下,其中所有三匹马都呈蓝色,因为它们都不是种用马
MATCH (h1:Horse {name: 'Scorpius'})
MATCH (h2:Horse {name: 'Tucana'})
MATCH (h3:Horse {name: 'Aries'})
MATCH (p1)-[r1:BREEDER_OF|OWNER_OF|TENANT_OF]-> (h1)
MATCH (p2)-[r2:BREEDER_OF|OWNER_OF|TENANT_OF]-> (h2)
MATCH (p3)-[r3:BREEDER_OF|OWNER_OF|TENANT_OF]-> (h3)
RETURN h1,h2,h3,p1,p2,p3,r1,r2,r3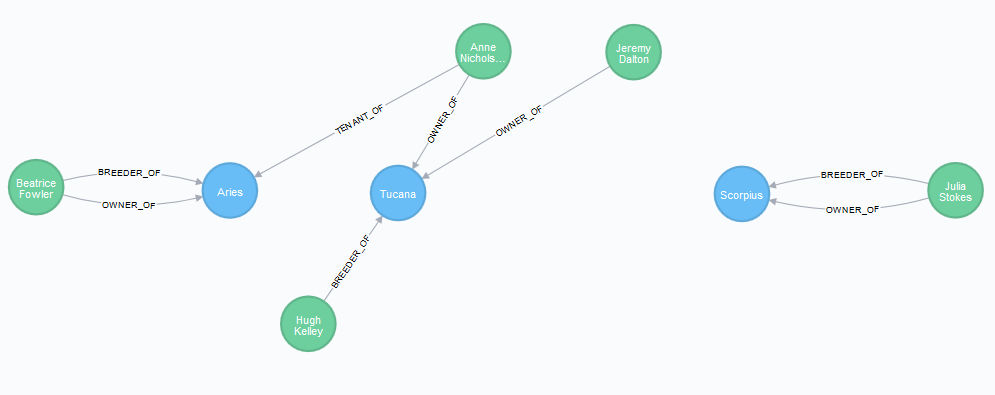
为了得到一匹新的马驹,Tucana 和 Scorpius 必须成为种用马
MATCH (h:Horse {name: 'Tucana'})
WHERE h.gender = 'F' AND NOT h:Mare
SET h:Mare
RETURN h.name as MareName, labels(h) as LabelsMATCH (h:Horse {name: 'Scorpius'})
WHERE h.gender = 'M' AND NOT h:Stud
SET h:Stud
RETURN h.name as StudName, labels(h) as Labels现在的情况如下,其中 Scorpius 作为种马显示为红色,Tucana 作为母马显示为紫色
MATCH (h1:Horse {name: 'Scorpius'})
MATCH (h2:Horse {name: 'Tucana'})
MATCH (h3:Horse {name: 'Aries'})
MATCH (p1)-[r1:BREEDER_OF|OWNER_OF|TENANT_OF]-> (h1)
MATCH (p2)-[r2:BREEDER_OF|OWNER_OF|TENANT_OF]-> (h2)
MATCH (p3)-[r3:BREEDER_OF|OWNER_OF|TENANT_OF]-> (h3)
RETURN h1,h2,h3,p1,p2,p3,r1,r2,r3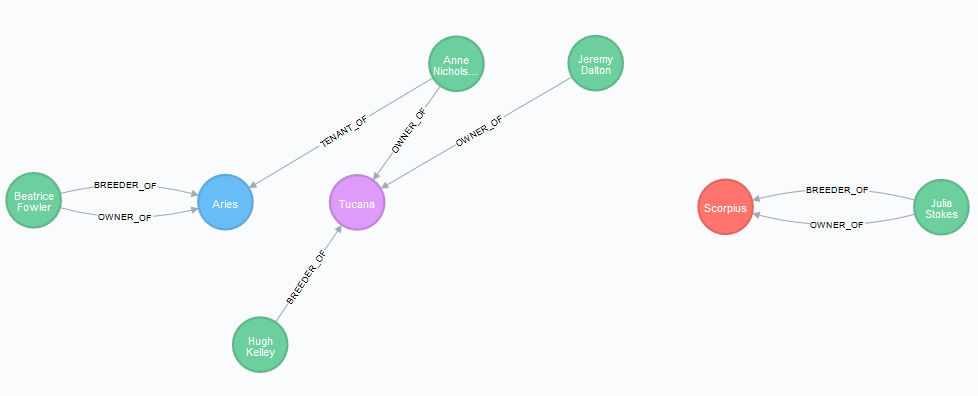
假设 Tucana 和 Scorpius 生育了一匹马驹,名叫 Saturn
MATCH (sire:Stud {name: 'Scorpius'})
MATCH (dam:Mare {name: 'Tucana'})
OPTIONAL MATCH (dam)<-[:SIRE_OF]-(damssire)
CREATE (foal:Horse {name: 'Saturn', birth_year: toInteger(2018), gender: 'M', mantle: 'bay'})
CREATE (dam)-[:DAM_OF]->(foal)
CREATE (sire)-[:SIRE_OF]->(foal)
WITH sire, dam, damssire, foal
MATCH (dam)<-[ownshp:OWNER_OF]-(owner)
OPTIONAL MATCH (dam)<-[tenshp:TENANT_OF]-(tenant)
WITH sire, dam, damssire, foal, coalesce(tenant, owner) as breeder, coalesce(tenshp, ownshp) as quote
CREATE (breeder)-[:BREEDER_OF {breed_perc: quote.property_perc}]->(foal)
CREATE (breeder)-[:OWNER_OF {property_perc: quote.property_perc}]->(foal)
RETURN DISTINCT 'Foal registered: ' + foal.name + ', by ' + sire.name + ' out of ' + dam.name + ' (' + damssire.name + ')' as NewFoal新的情况如下
MATCH (h1:Horse {name: 'Scorpius'})
MATCH (h2:Horse {name: 'Tucana'})
MATCH (h3:Horse {name: 'Aries'})
MATCH (h4:Horse {name: 'Saturn'})
MATCH (p1)-[r1:BREEDER_OF|OWNER_OF|TENANT_OF]-> (h1)
MATCH (p2)-[r2:BREEDER_OF|OWNER_OF|TENANT_OF]-> (h2)
MATCH (p3)-[r3:BREEDER_OF|OWNER_OF|TENANT_OF]-> (h3)
MATCH (p4)-[r4:BREEDER_OF|OWNER_OF|TENANT_OF]-> (h4)
MATCH (h1)-[r5:SIRE_OF]->(h4)<-[r6:DAM_OF]-(h2)
RETURN h1,h2,h3,h4,p1,p2,p3,p4,r1,r2,r3,r4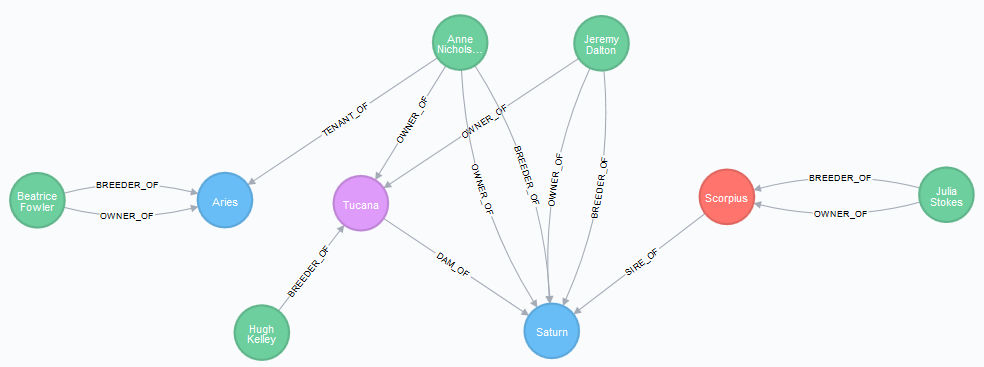
你可以看到 Saturn 的育种者和所有者是其母系 Tucana 的所有者 Anne Nicholson 和 Jeremy Dalton,他们对母马拥有的权利百分比相同,分别为 60% 和 40%
MATCH (h:Horse {name: 'Saturn'})
MATCH (h)<-[r:OWNER_OF]-(p)
RETURN p.name, r.property_percMATCH (h:Horse {name: 'Saturn'})
MATCH (h)<-[r:BREEDER_OF]-(p)
RETURN p.name, r.breed_perc现在假设这匹新马驹被出售给了 Julia Stokes、Hugh Kelley 和 Philip Lindsey(最后一位是数据库中的新人物),产权百分比分别为 25%、25% 和 50%。
MATCH (h:Horse {name: 'Saturn'})
OPTIONAL MATCH (h)<-[oldOwnshp:OWNER_OF]-()
DELETE oldOwnshp
WITH DISTINCT h, [{name:'Julia Stokes', property_perc: toFloat(25)}, {name:'Hugh Kelley', property_perc: toFloat(25)}, {name:'Philip Lindsey', property_perc: toFloat(50)}] AS purchaserList
UNWIND purchaserList AS purchaser
MERGE (p:Person {name: purchaser.name})
ON CREATE SET p.property_perc = purchaser.property_perc
ON MATCH SET p.property_perc = purchaser.property_perc
CREATE (p)-[newOwnshp:OWNER_OF {property_perc: p.property_perc}]->(h)
REMOVE p.property_perc
RETURN p.name, type(newOwnshp), newOwnshp.property_perc最终情况如下
MATCH (h1:Horse {name: 'Scorpius'})
MATCH (h2:Horse {name: 'Tucana'})
MATCH (h3:Horse {name: 'Aries'})
MATCH (h4:Horse {name: 'Saturn'})
MATCH (p1)-[r1:BREEDER_OF|OWNER_OF|TENANT_OF]-> (h1)
MATCH (p2)-[r2:BREEDER_OF|OWNER_OF|TENANT_OF]-> (h2)
MATCH (p3)-[r3:BREEDER_OF|OWNER_OF|TENANT_OF]-> (h3)
MATCH (p4)-[r4:BREEDER_OF|OWNER_OF|TENANT_OF]-> (h4)
MATCH (h1)-[]->(h4)<-[]-(h2)
RETURN h1,h2,h3,h4,p1,p2,p3,p4,r1,r2,r3,r4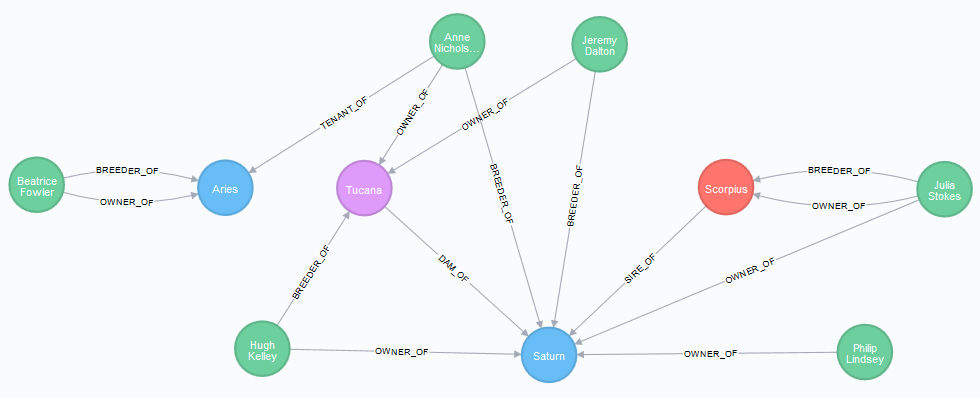
我们可以检查产权是否正确
MATCH (h:Horse {name: 'Saturn'})
MATCH (h)<-[r:OWNER_OF]-(p)
RETURN p.name, r.property_perc没错!
通过这些指令,我们可以构建一个应用程序,让我们以自然而轻松的方式管理血统簿。
数据查询
用户通常向血统簿询问的查询与马匹信息、其祖先和后代以及拥有或管理它的人员有关。让我们看看其中一些查询。
-
马匹血统
血统的主要部分显示马匹及其父母和祖父母(通常也包括曾祖父母)的数据
MATCH (h:Horse {name: 'Saturn'})
OPTIONAL MATCH (h)<-[:DAM_OF]-(dam:Mare)
OPTIONAL MATCH (h)<-[:SIRE_OF]-(sire:Stud)
OPTIONAL MATCH (dam)<-[:DAM_OF]-(damsdam:Mare)
OPTIONAL MATCH (dam)<-[:SIRE_OF]-(damssire:Stud)
OPTIONAL MATCH (sire)<-[:DAM_OF]-(siresdam:Mare)
OPTIONAL MATCH (sire)<-[:SIRE_OF]-(siressire:Stud)
RETURN h.name as Name, h.gender as Gender, h.birth_year as Birth_year, h.mantle as Mantle, sire.name as Sire_name, sire.birth_year as Sire_birth_year, sire.mantle as Sire_mantle, siressire.name as Sire_of_sire, siresdam.name as Dam_of_sire, dam.name as Dam_name, dam.birth_year as Dam_birth_year, dam.mantle as Dam_mantle, damssire.name as Sire_of_dam, damsdam.name as Dam_of_dam-
母系血统
血统的另一个典型部分与母系血统有关,即直至第三代(或第四代)的母亲列表
MATCH (h:Horse {name: 'Saturn'})
OPTIONAL MATCH (h)<-[:DAM_OF]-(d1:Horse)
OPTIONAL MATCH (d1)<-[:DAM_OF]-(d2:Horse)
OPTIONAL MATCH (d2)<-[:DAM_OF]-(d3:Horse)
RETURN h.name AS Name, h.birth_year AS Birth, d1.name AS FirstMother, d1.birth_year AS FMBirth, d2.name AS SecondMother, d2.birth_year AS SMBirth, d3.name AS ThirdMother, d3.birth_year AS TMBirth-
马匹后代
显然,如果一匹马有后代,了解它们的数量以及父母是谁是很重要的
MATCH (h:Horse {name: 'Cepheus'})
OPTIONAL MATCH (h)-->(d:Horse)
OPTIONAL MATCH (d)<--(p:Horse) WHERE p.name <> h.name
RETURN h.name as Name, h.gender as Gender, h.birth_year as Birth, h.mantle as Mantle, d.name as Descendant, d.gender as DGender, d.birth_year as DBirth, p.name as DParent, p.birth_year as DParent_birth
ORDER BY d.birth_yearMATCH (h:Horse {name: 'Virgo'})
OPTIONAL MATCH (h)-->(d:Horse)
OPTIONAL MATCH (d)<--(p:Horse) WHERE p.name <> h.name
RETURN h.name as Name, h.gender as Gender, h.birth_year as Birth, h.mantle as Mantle, d.name as Descendant, d.gender as DGender, d.birth_year as DBirth, p.name as DParent, p.birth_year as DParent_birth
ORDER BY d.birth_year结论
我们已经看到,在图上查看血统簿的数据是多么容易和自然,以及管理这些数据的指令是多么清晰。
我希望您喜欢这篇 gist,并从中获得一些实际应用程序的启示。正如我之前所说,数据模型可以得到很大程度的增强,例如为实例添加额外属性或重构某些方面,如时间或国籍(出生年份或国家作为节点):从重构的角度来看,您会发现 Neo4j 允许您以比关系型 DBMS 更流畅、更灵活的方式增强节点和关系上的信息,一方面保留了真正的关系结构的优点,另一方面也享受了自由结构数据库的优势。
祝您使用愉快!
此页面有帮助吗?